记一次APK分析
一、Java层分析
先jadx打开看看Java层,结果发现有壳
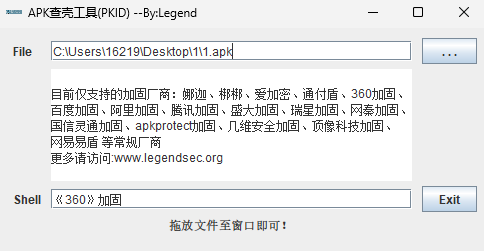
360壳,直接用frida-dexdump一把梭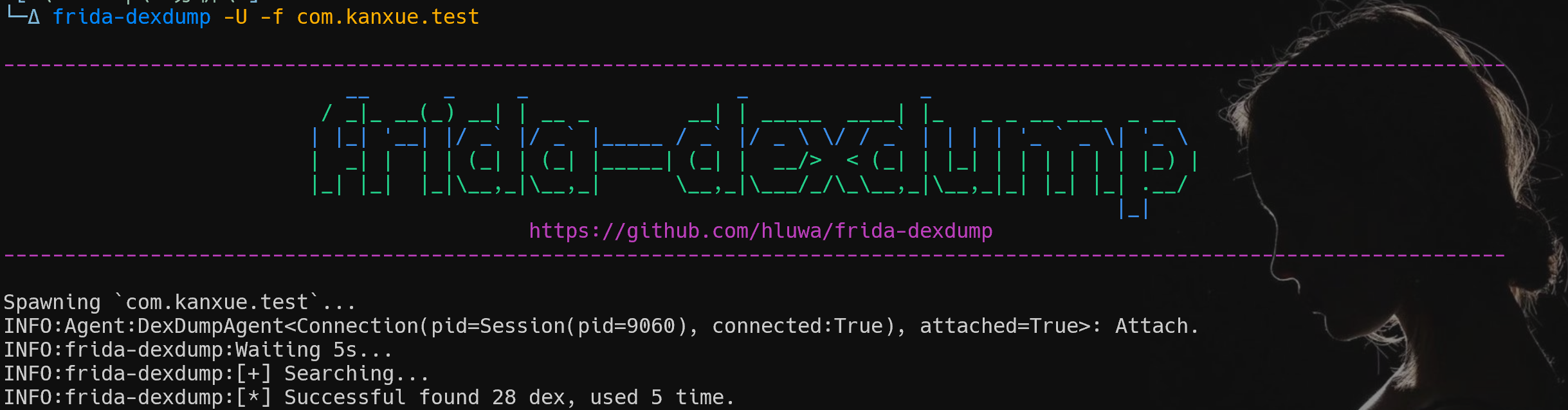
脱完壳之后直接分析class.dex,如果jadx反编译报错说checksum有问题的话,这样操作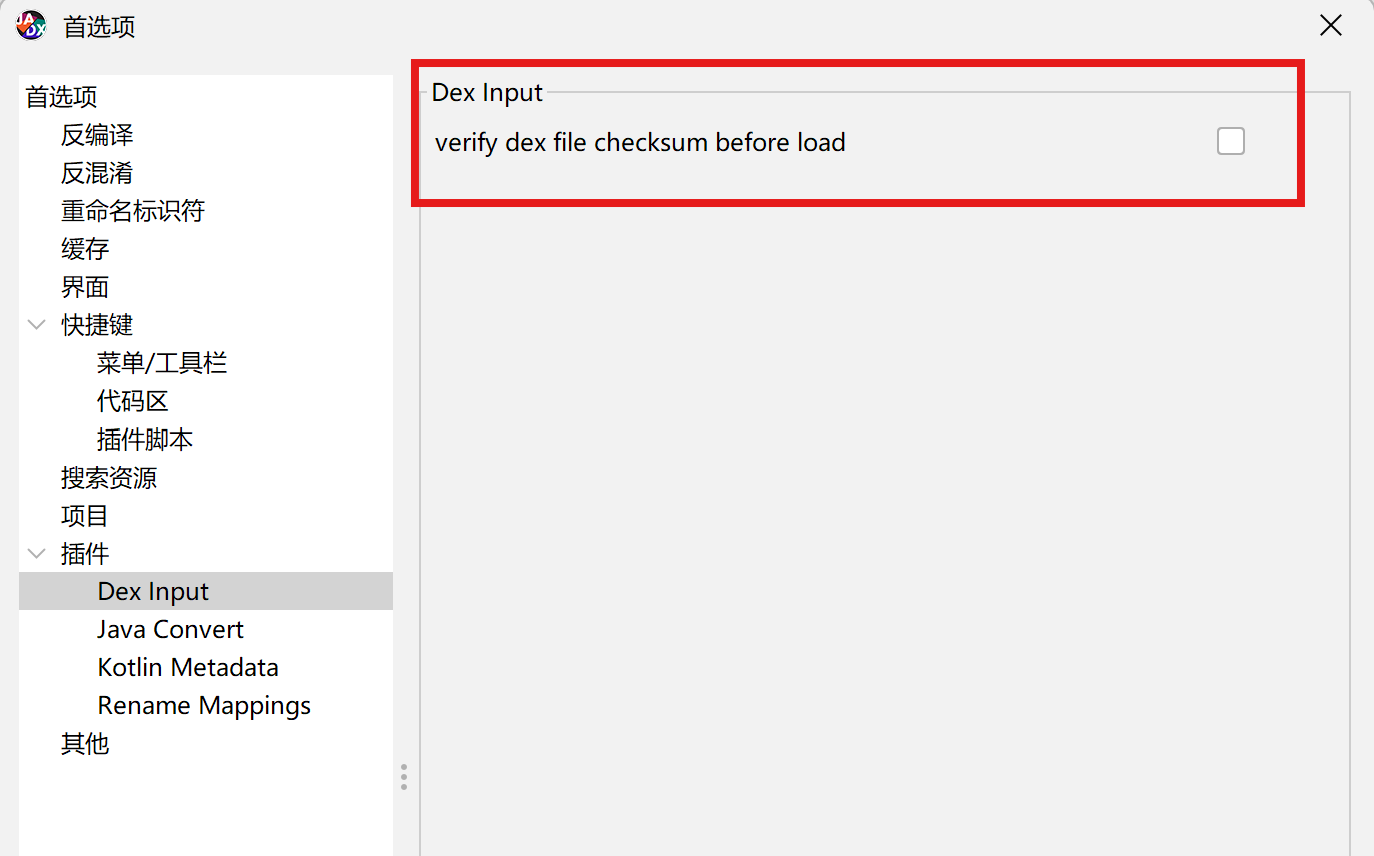
把这个关了就好了,就可以正常反编译了
接下来就直接分析com.kanxue.test.MainActivity
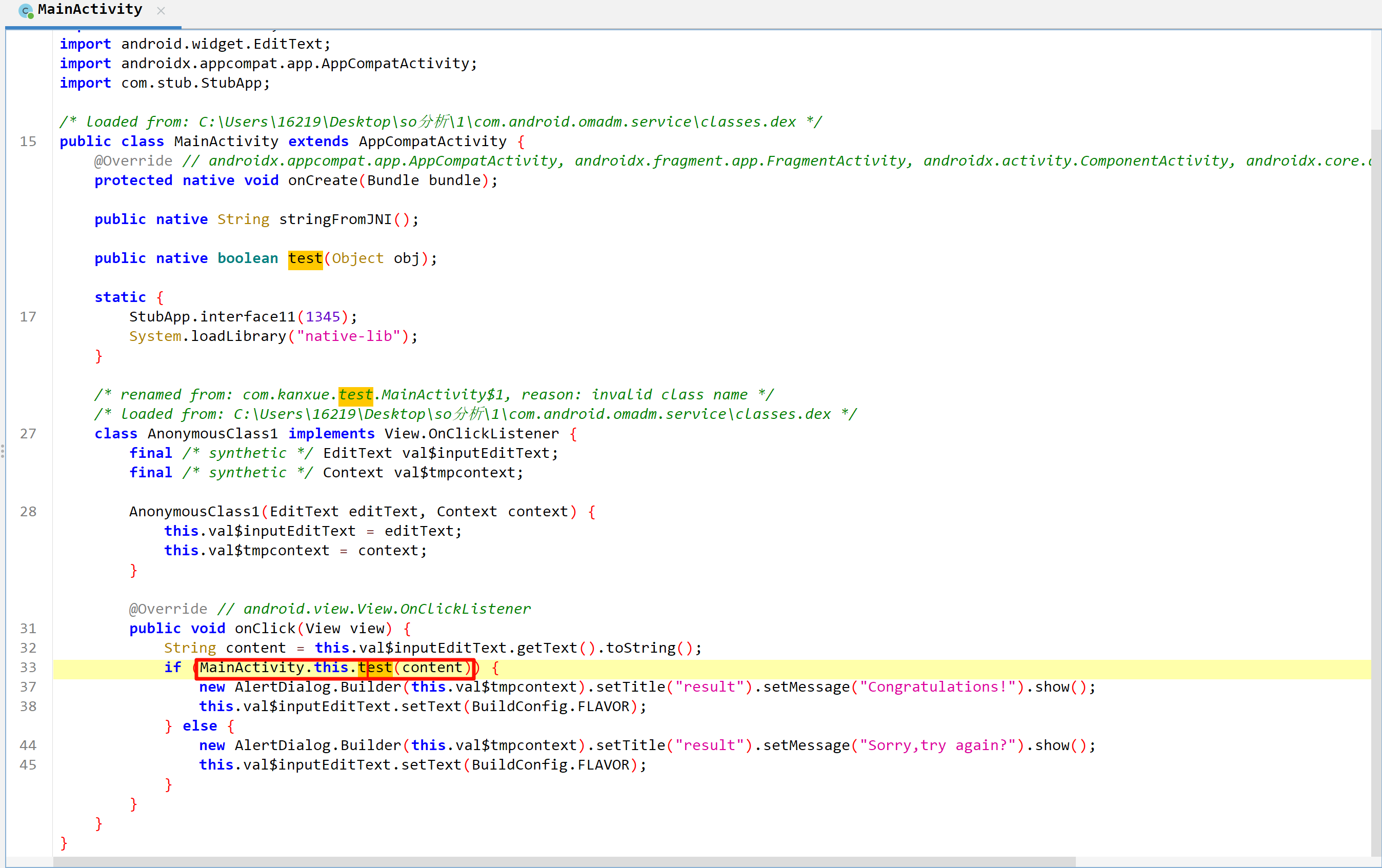
很显然,check逻辑都写在so层了
二、so层分析
2.1JNI静态注册与动态注册
JNI注册方法分为静态注册和动态注册,静态注册的方法可以在IDA的函数窗口或者导出表中直接找到,比较简单。动态注册的方法需要分析JNI_OnLoad函数,把libnative-lib.so拖进ida神器,分析Exports导出表,可知上图中的stringFromJNI方法是静态注册,而test方法是动态注册。
导出表
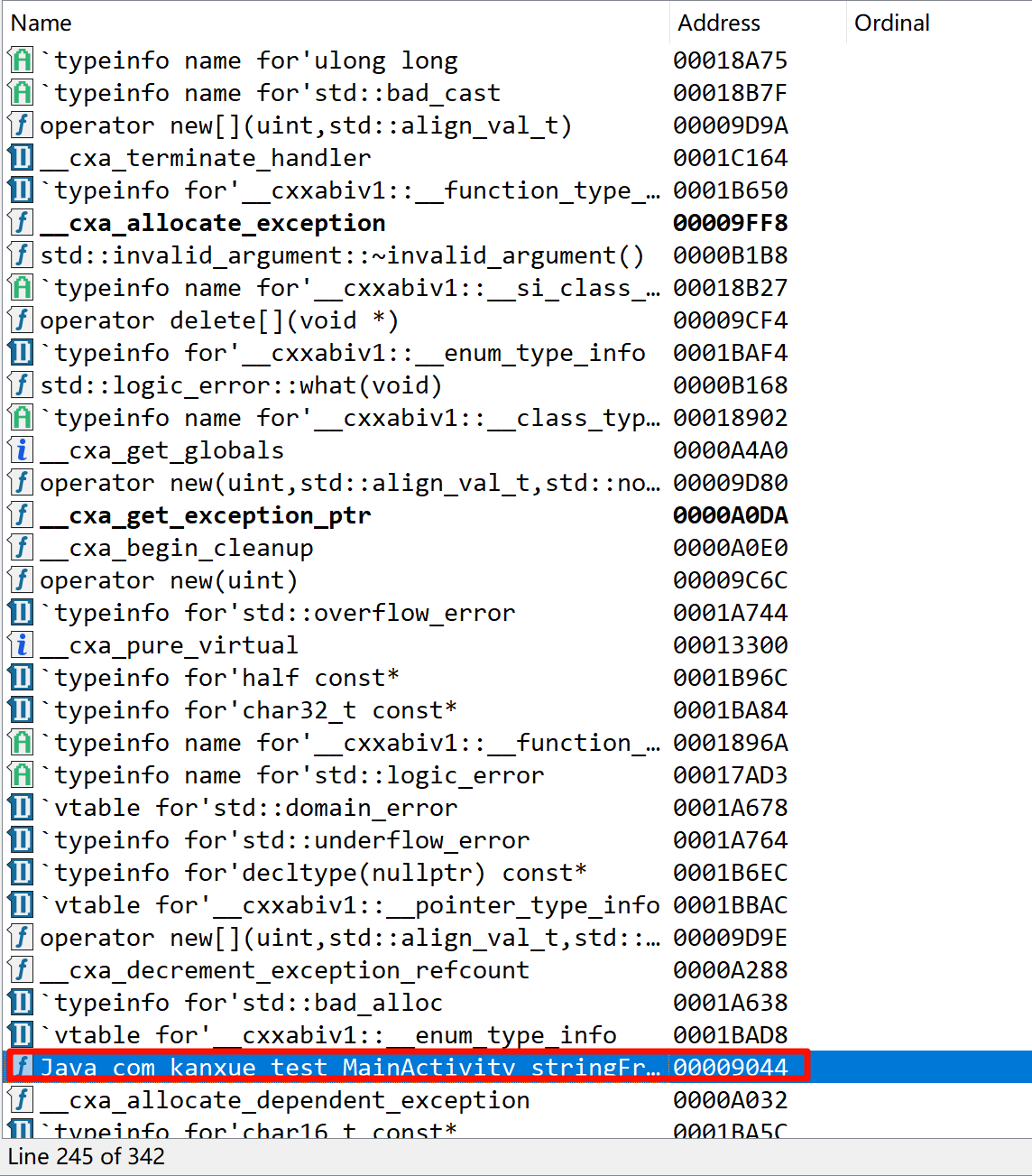
函数窗口也可以找到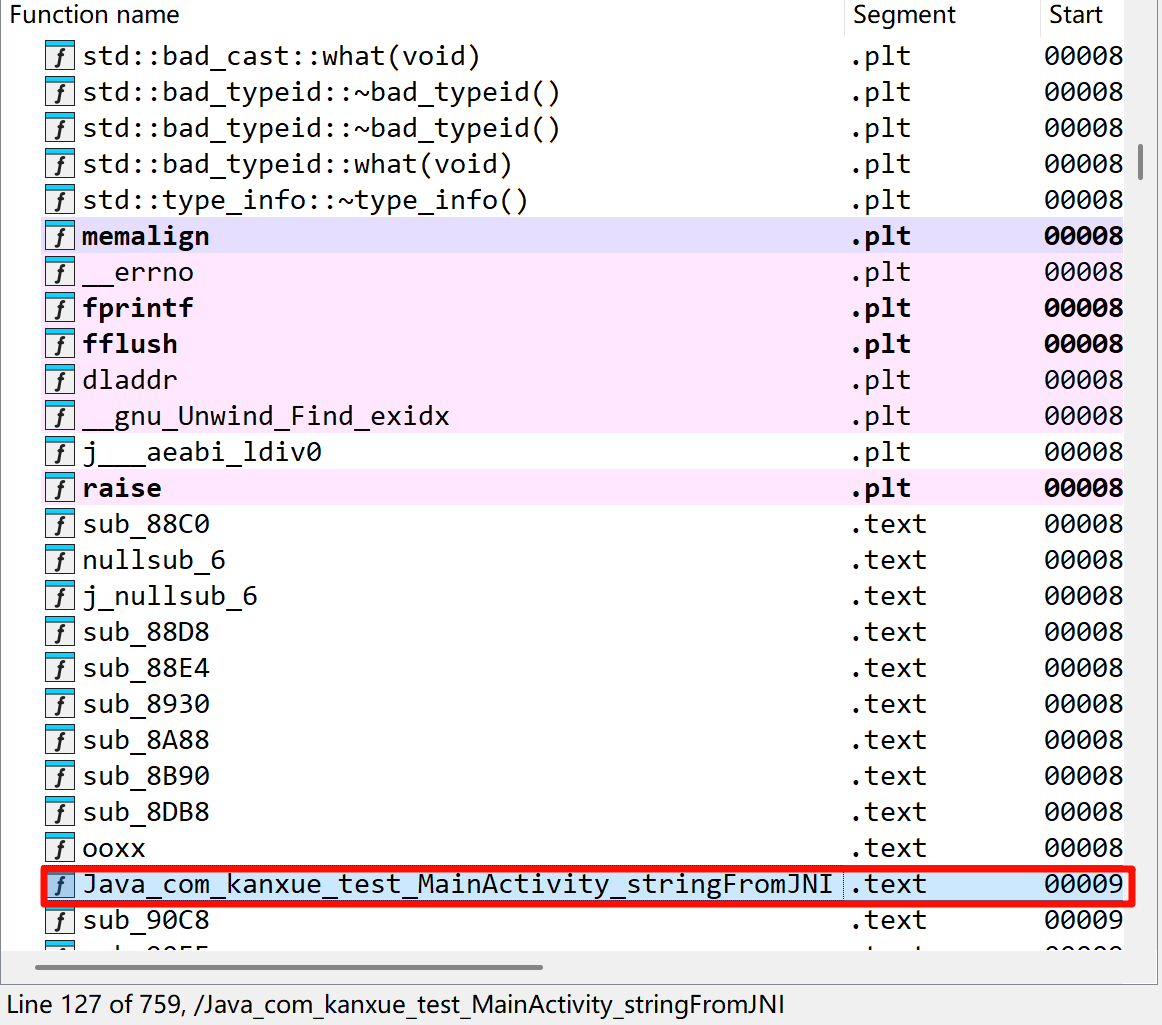
查看段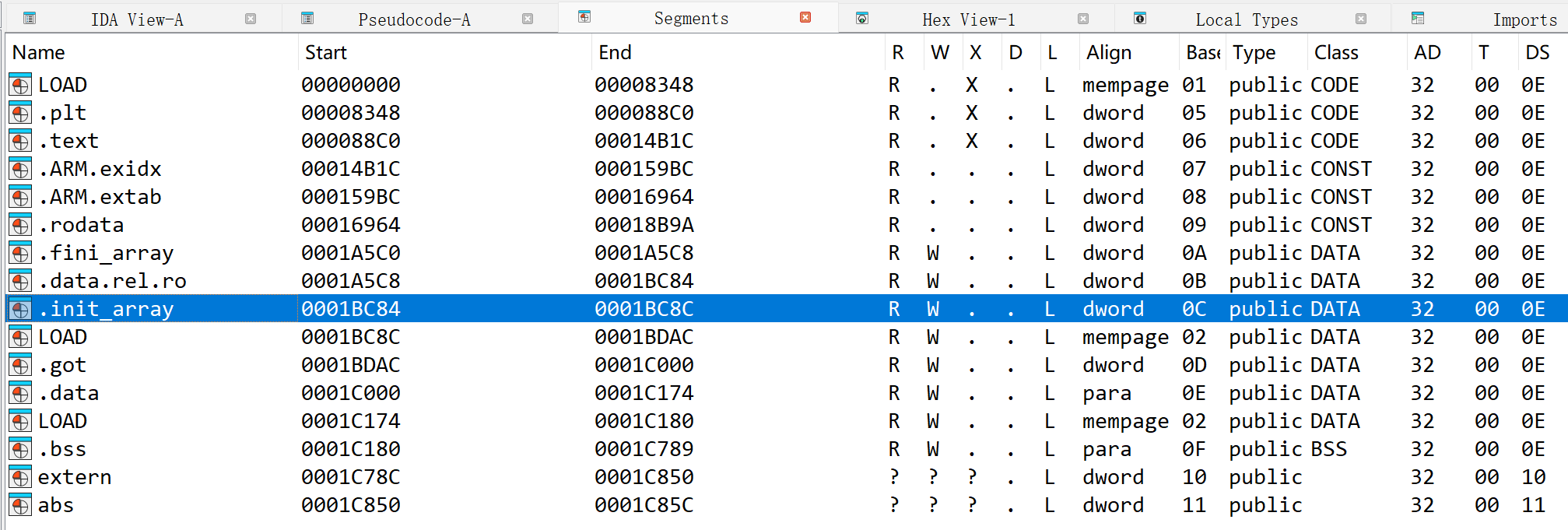
可以看到也是存在**.init_aray**段,即test方法是动态注册的
在分析JNI_OnLoad函数之前,先回顾一下JNI方法动态注册的流畅:
//第一步,实现JNI_OnLoad方法
JNIEXPORT jint JNI_OnLoad(JavaVM* jvm, void* reserved){
//第二步,获取JNIEnv
JNIEnv* env = NULL;
if(jvm->GetEnv((void**)&env, JNI_VERSION_1_6) != JNI_OK){
return JNI_FALSE;
}
//第三步,获取注册方法所在Java类的引用
jclass clazz = env->FindClass("com/NshIdE/MainActivity");
if (!clazz){
return JNI_FALSE;
}
//第四步,动态注册native方法
if(env->RegisterNatives(clazz, gMethods, sizeof(gMethods)/sizeof(gMethods[0]))){
return JNI_FALSE;
}
return JNI_VERSION_1_6;
}
其中第四步gMethods变量是JNINativeMethod结构体,用于映射Java方法与C/C++函数的关系,其定义如下:
typedef struct {
const char* name; //动态注册的Java方法名
const char* signature; //描述方法参数和返回值
void* fnPtr; //指向实现Java方法的C/C++函数指针
} JNINativeMethod;
2.2JNI_OnLoad分析
ida中找到JNI_OnLoad方法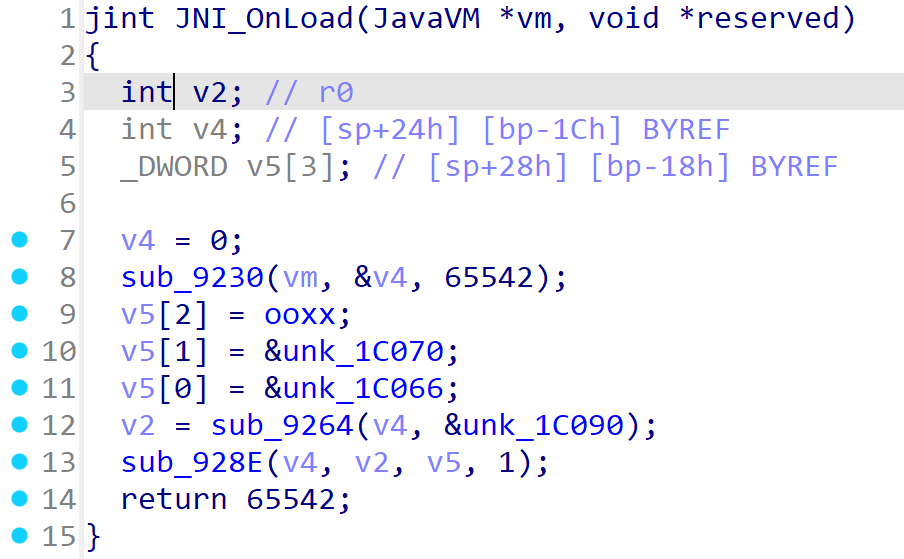
这里ida识别出来了第一个参数是JavaVM指针类型,所以就可以不用手动修复了,跟进sub_9230函数
这里就没有识别出来,所以需要手动修复一下,选中int,然后按快捷键Y,将int改成JavaVM*
修复之后如下
同时,代码中的结构体也被识别出来了
然后回到JNI_OnLoad函数中,从JNI动态注册流程可知,jvm->GetEnv的第一个参数是JNIEnv指针类型,对应sub_9230函数的伪代码中的a2,在JNI_OnLoad函数中则对应的是v4,手动修复一下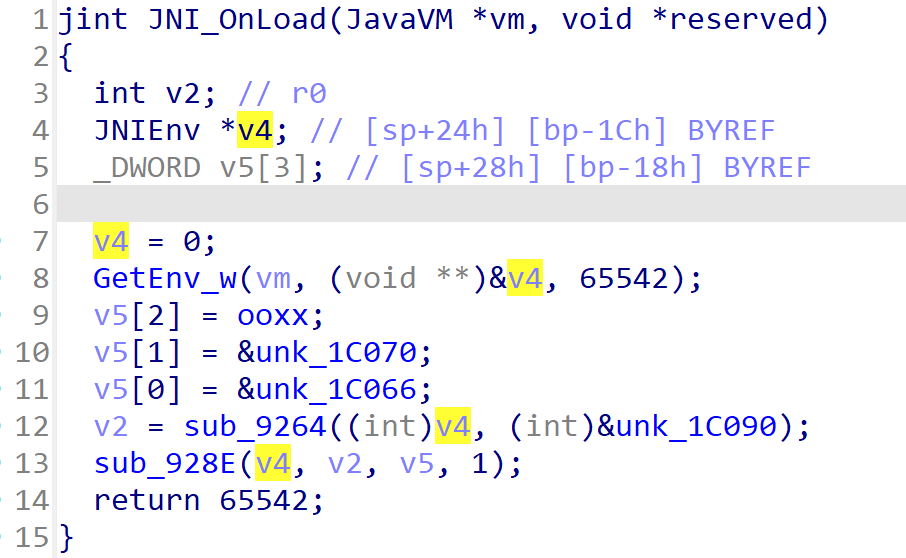
那么跟进到sub_9264函数中也是一样,手动修复一下
继续分析sub_928E函数,这个函数自然就是env->RegisterNatives了,一样手动修复一下
最后回到JNI_OnLoad函数,重新按F5重新让ida反编译一下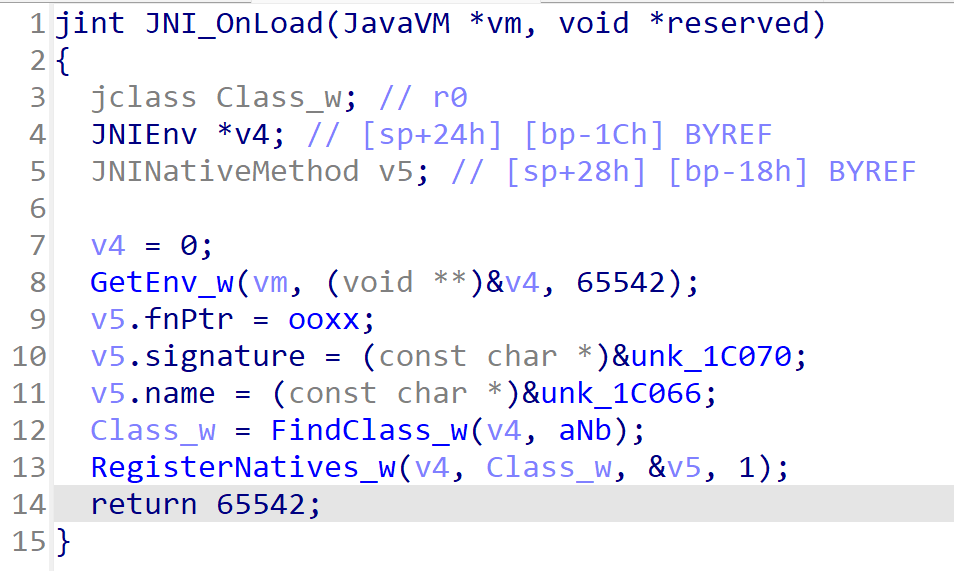
这样就很清晰了。v5指针指向的就是JNINativeMethod结构体,跟进unk_1C066查看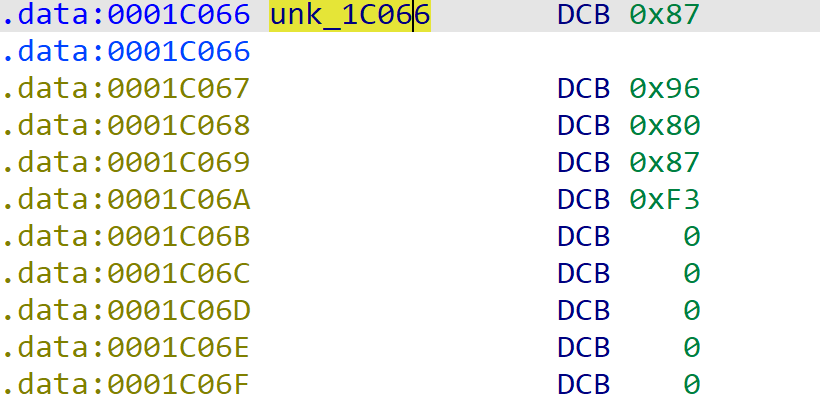
很明显,值被加密了
2.3.init段分析
在链接so共享目标文件的时候,如果so中存在.init和.init_array段,则会先执行.init和.init_array段的函数,然后再执行JNI_OnLoad函数。通过静态分析可知,JNI_OnLoad函数中的v5指针指向的地址上的变量值是加密状态,但是在实际运行当中,v5指针指向的地址上的值应该是解密状态,所以解密操作应该在JNI_OnLoad函数运行之前,.init或者**.init_array**段上的函数
还是一样,查看段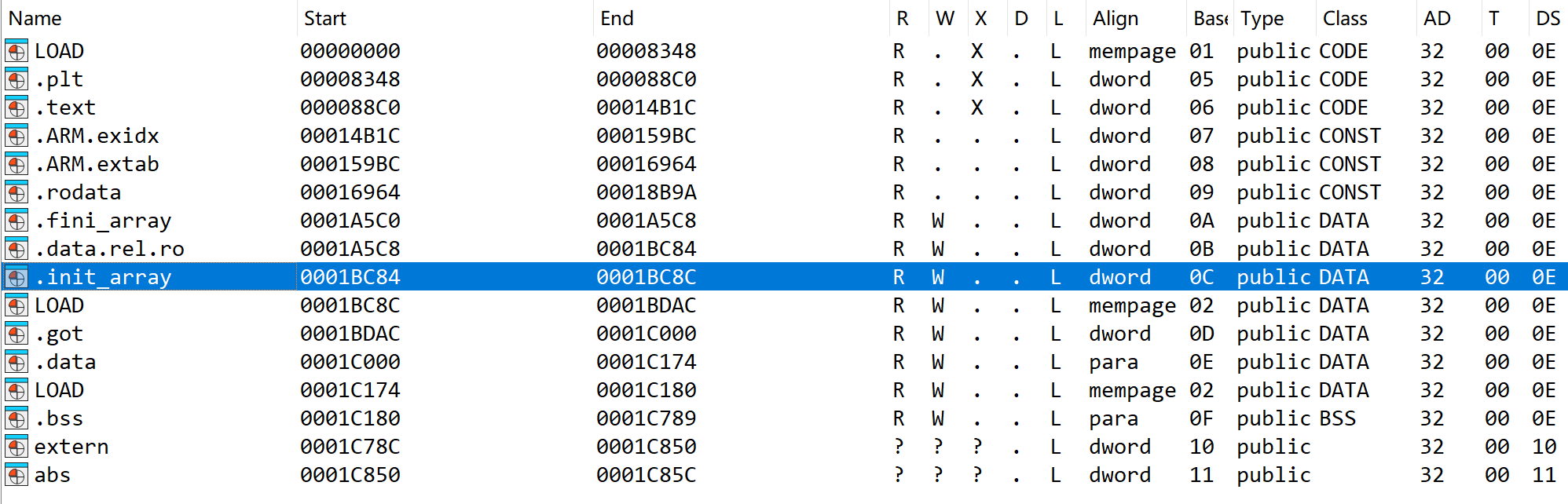
定位.init_array段,发现这里定义了一个解密函数
跟进分析伪代码
unsigned int datadiv_decode4192348989750430380()
{
unsigned int n0x10; // r0
unsigned int n0x1B; // r0
unsigned int n0xA; // r0
unsigned int n0xE; // r0
unsigned int n4; // r0
unsigned int n0x15; // r0
unsigned int n0x1C; // r0
unsigned int n0xD; // r0
int v8; // r0
unsigned int n0xB; // r0
int v10; // r0
unsigned int n0x15_1; // r0
unsigned int n0x1C_1; // r0
unsigned int n0xC; // r0
unsigned int n0x43; // r0
unsigned int n0x43_1; // [sp+0h] [bp-3Ch]
unsigned int n0xC_1; // [sp+4h] [bp-38h]
unsigned int n0x1C_3; // [sp+8h] [bp-34h]
unsigned int n0x15_3; // [sp+Ch] [bp-30h]
int v19; // [sp+10h] [bp-2Ch]
unsigned int n0xB_1; // [sp+14h] [bp-28h]
int v21; // [sp+18h] [bp-24h]
unsigned int n0xD_1; // [sp+1Ch] [bp-20h]
unsigned int n0x1C_2; // [sp+20h] [bp-1Ch]
unsigned int n0x15_2; // [sp+24h] [bp-18h]
unsigned int n4_1; // [sp+28h] [bp-14h]
unsigned int n0xE_1; // [sp+2Ch] [bp-10h]
unsigned int n0xA_1; // [sp+30h] [bp-Ch]
unsigned int n0x1B_1; // [sp+34h] [bp-8h]
unsigned int n0x10_1; // [sp+38h] [bp-4h]
n0x10_1 = 0;
do
{
n0x10 = n0x10_1;
byte_1C010[n0x10_1++] ^= 0x14u;
}
while ( n0x10 < 0x10 );
n0x1B_1 = 0;
do
{
n0x1B = n0x1B_1;
byte_1C030[n0x1B_1++] ^= 0xD3u;
}
while ( n0x1B < 0x1B );
n0xA_1 = 0;
do
{
n0xA = n0xA_1;
byte_1C04C[n0xA_1++] ^= 0x63u;
}
while ( n0xA < 0xA );
n0xE_1 = 0;
do
{
n0xE = n0xE_1;
byte_1C057[n0xE_1++] ^= 0x3Fu;
}
while ( n0xE < 0xE );
n4_1 = 0;
do
{
n4 = n4_1;
byte_1C066[n4_1++] ^= 0xF3u;
}
while ( n4 < 4 );
n0x15_2 = 0;
do
{
n0x15 = n0x15_2;
byte_1C070[n0x15_2++] ^= 0xFAu;
}
while ( n0x15 < 0x15 );
n0x1C_2 = 0;
do
{
n0x1C = n0x1C_2;
aNb[n0x1C_2++] ^= 0x2Du;
}
while ( n0x1C < 0x1C );
n0xD_1 = 0;
do
{
n0xD = n0xD_1;
byte_1C0AD[n0xD_1++] ^= 0xF5u;
}
while ( n0xD < 0xD );
v21 = 0;
do
{
v8 = v21;
byte_1C0BB[v21++] ^= 0xF8u;
}
while ( !v8 );
n0xB_1 = 0;
do
{
n0xB = n0xB_1;
byte_1C0BD[n0xB_1++] ^= 0xE6u;
}
while ( n0xB < 0xB );
v19 = 0;
do
{
v10 = v19;
byte_1C0C9[v19++] ^= 0x66u;
}
while ( !v10 );
n0x15_3 = 0;
do
{
n0x15_1 = n0x15_3;
byte_1C0D0[n0x15_3++] ^= 0x2Du;
}
while ( n0x15_1 < 0x15 );
n0x1C_3 = 0;
do
{
n0x1C_1 = n0x1C_3;
byte_1C0F0[n0x1C_3++] ^= 9u;
}
while ( n0x1C_1 < 0x1C );
n0xC_1 = 0;
do
{
n0xC = n0xC_1;
byte_1C10D[n0xC_1++] ^= 0x9Eu;
}
while ( n0xC < 0xC );
n0x43_1 = 0;
do
{
n0x43 = n0x43_1;
byte_1C120[n0x43_1++] ^= 0xDBu;
}
while ( n0x43 < 0x43 );
return n0x43;
}
就是一个异或,解密一下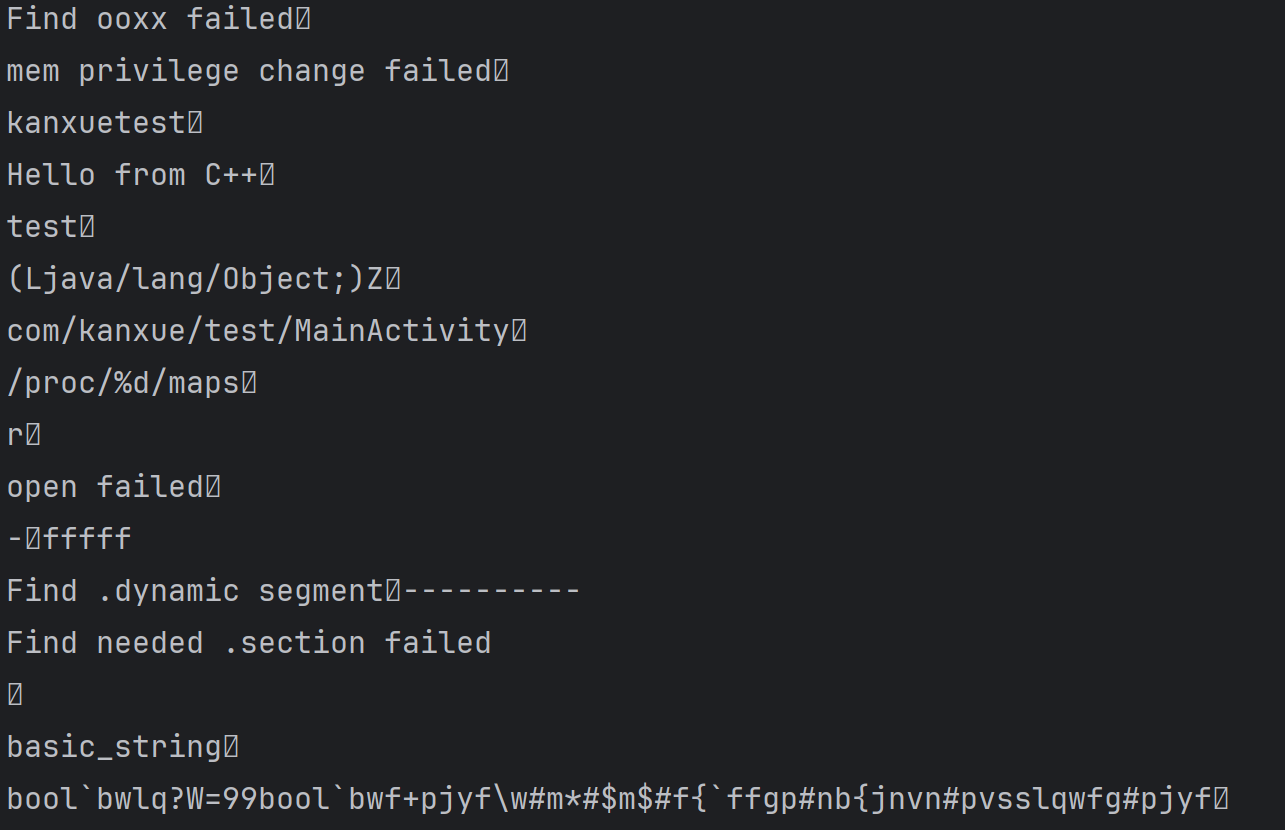
这些值解出来正好对应Java中的test方法以及其参数和返回值
JNINativeMethod结构体的第三个成员指向实现Java方法的C/C++函数地址,so文件的.data段一般是保存已经初始化的全局静态变量和局部变量,动态注册函数的信息一般存放在**.data.rel.ro.local段。交叉引用byte_1C066或者byte_1C070变量,跳转到.data.rel.ro**段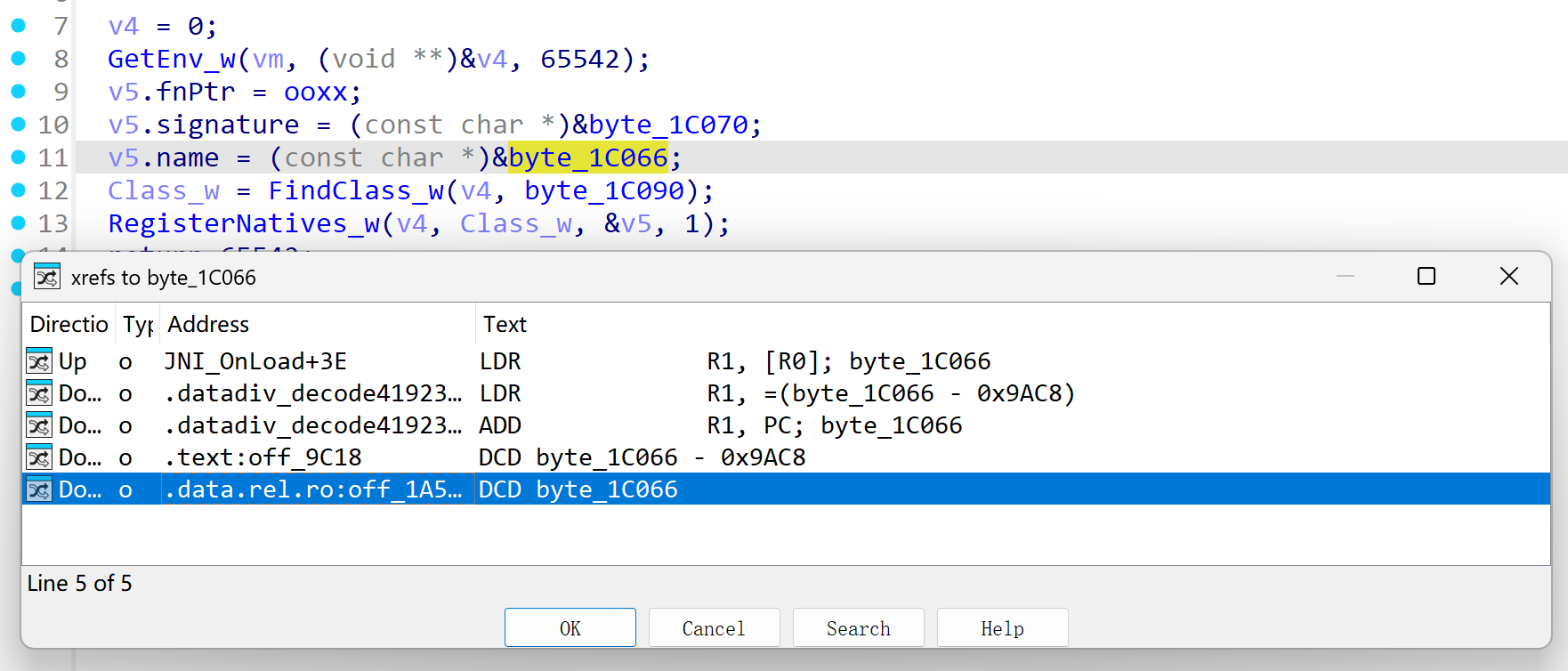
可以看到
off_1A5C8的值为byte_1C066(动态注册的方法名test),off_1A5CC的值为byte_1C070,那off_1A5D0的值ooxx一定就是test方法的注册地址,正好对应于JNINativeMethod结构体的三个字段。
2.4函数逻辑分析
跳转到ooxx函数,看到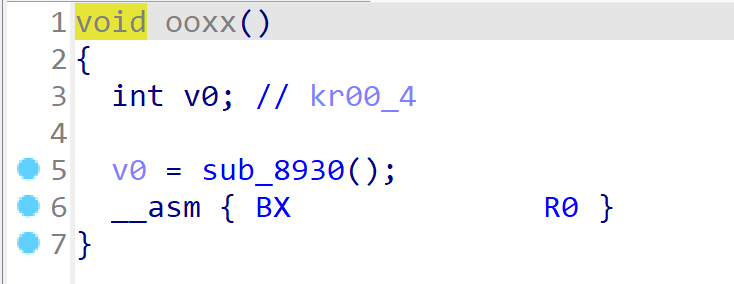
这里是ida识别错误了,继续跟进**sub_8930()**函数
int sub_8930()
{
unsigned int v0; // r0
int v1; // r1
_BYTE *i; // [sp+18h] [bp-40h]
unsigned int v4; // [sp+1Ch] [bp-3Ch]
int v5; // [sp+20h] [bp-38h]
size_t len; // [sp+24h] [bp-34h]
void *addr; // [sp+2Ch] [bp-2Ch]
int v8; // [sp+30h] [bp-28h]
int v9; // [sp+3Ch] [bp-1Ch] BYREF
int v10; // [sp+40h] [bp-18h]
char ooxx_[8]; // [sp+44h] [bp-14h] BYREF
strcpy(ooxx_, "ooxx");
v8 = sub_8A88();
if ( sub_8B90(v8, ooxx_, &v9) == -1 )
{
sub_8DB8(&unk_1C010);
}
else
{
addr = (void *)((v8 + v9) & 0xFFFFF000);
v0 = v8 + v9 + v10 - (_DWORD)addr;
v1 = (v0 >> 12) + 1;
if ( !(v0 << 20) )
v1 = v0 >> 12;
len = v1 << 12;
if ( mprotect(addr, v1 << 12, 7) )
sub_8DB8(&unk_1C030);
v5 = v8 + v9 + 59;
v4 = v8 + v9 + v10 - 61;
for ( i = (_BYTE *)v5; (unsigned int)i < v4; ++i )
*i ^= byte_1C180[(_DWORD)&i[-v5]];
if ( mprotect(addr, len, 5) )
sub_8DB8(&unk_1C030);
cacheflush(v8 + v9, v8 + v9 + v10, 0);
}
return _stack_chk_guard;
}
从上往下分析,跟进**sub_8A88()**函数
unsigned int sub_8A88()
{
FILE *stream; // [sp+18h] [bp-1040h]
__pid_t pid; // [sp+1Ch] [bp-103Ch]
const char *nptr; // [sp+20h] [bp-1038h]
unsigned int v4; // [sp+24h] [bp-1034h]
char s[4096]; // [sp+3Bh] [bp-101Dh] BYREF
char libnative_lib.so_[29]; // [sp+103Bh] [bp-1Dh] BYREF
v4 = 0;
strcpy(libnative_lib.so_, "libnative-lib.so");
pid = getpid();
sprintf(s, aKf, pid);
stream = fopen(s, &aKf[14]);
if ( stream )
{
while ( fgets(s, 4096, stream) )
{
if ( strstr(s, libnative_lib.so_) )
{
nptr = strtok(s, &aKf[28]);
v4 = strtoul(nptr, 0, 16);
break;
}
}
}
else
{
puts(&aKf[16]);
}
fclose(stream);
return v4;
}
其中的数据进行解密,我们在之前解密过了,是/proc/%d/maps,分析代码可知,这里就是在获取so文件映射在内存中的基地址。具体分析如下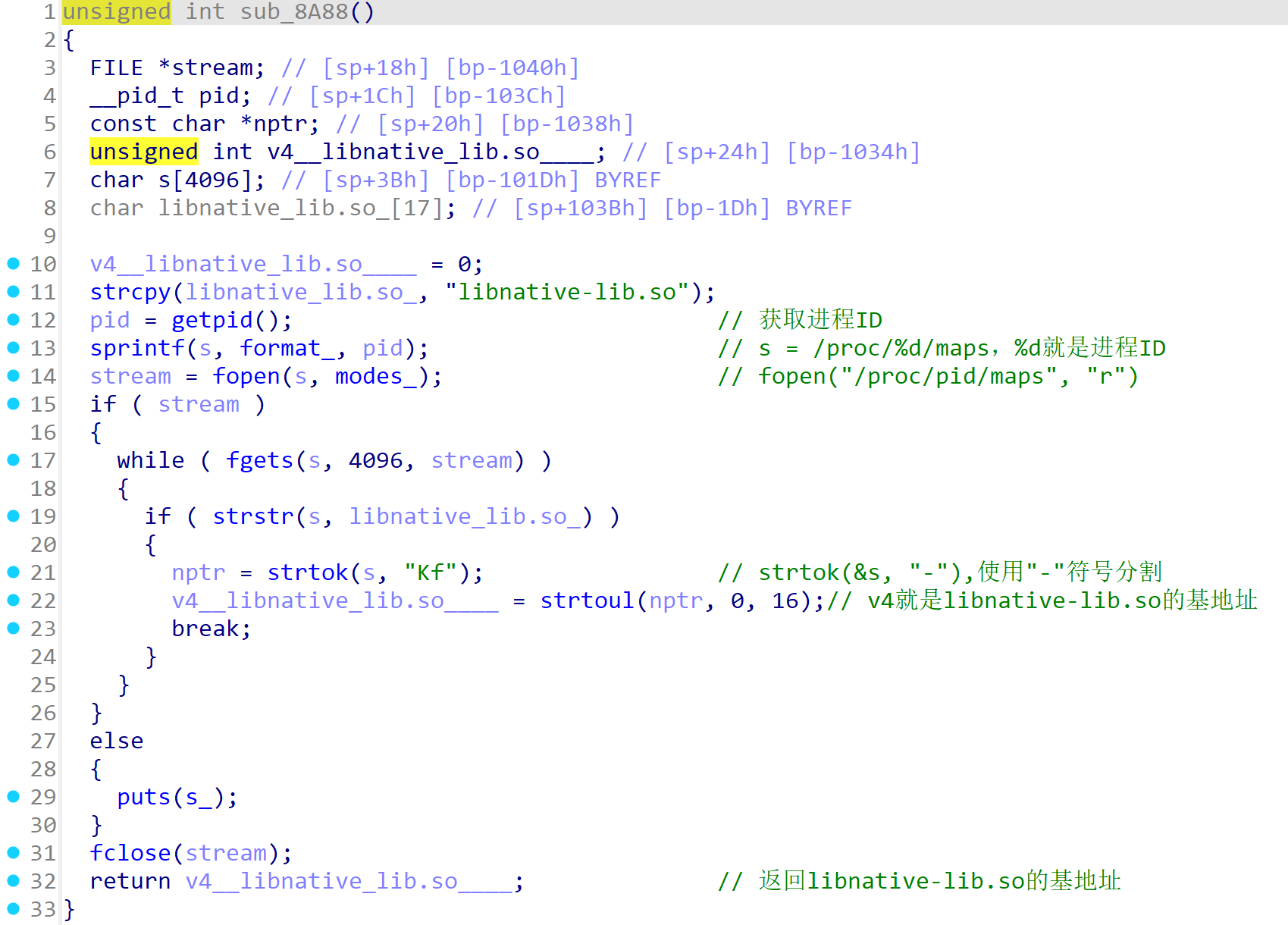
返回到sub_8930()函数,继续往下分析,跟进sub_8B90()函数,代码以及分析如下,该函数将libnative-lib.so的基地址和字符串ooxx作为参数传入,第三个参数用于保存返回结果。
这个函数的主要的功能就是在一个内存中映射的so文件中,利用 ELF 哈希表机制,找到指定函数(符号名)的地址与大小,并返回。
接下来是以可视化方式展现代码逻辑,核心逻辑就是上图中的代码
先分析第一句代码(第28行),首先是基地址+28(0x1C)获取程序头表偏移值52(0x34)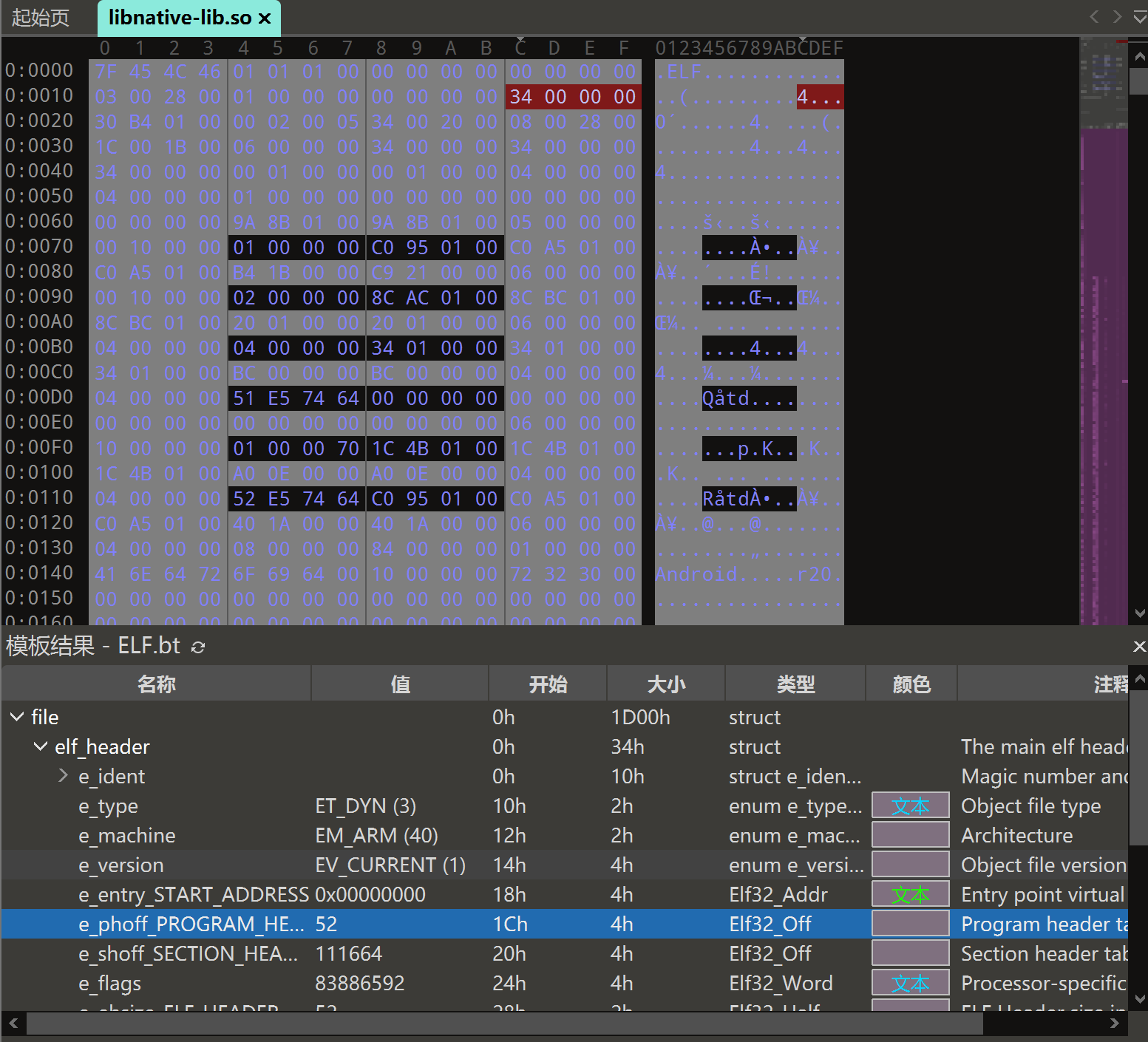
接着基地址+0x34,拿到程序头表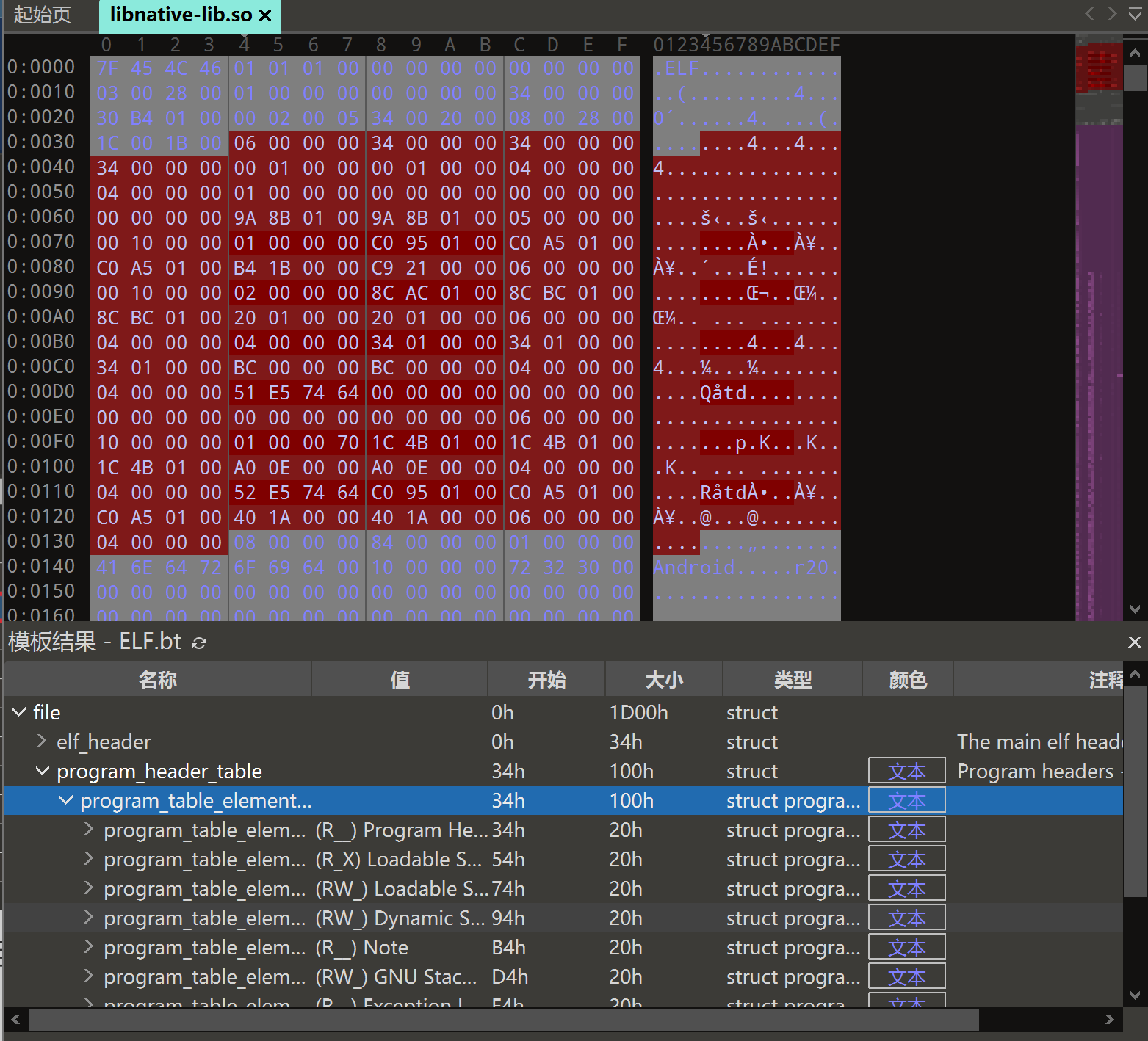
第一个for循环中的***(baseAddr + 0x2C)**是程序头表的数量,相当于程序执行试图中的Segment个数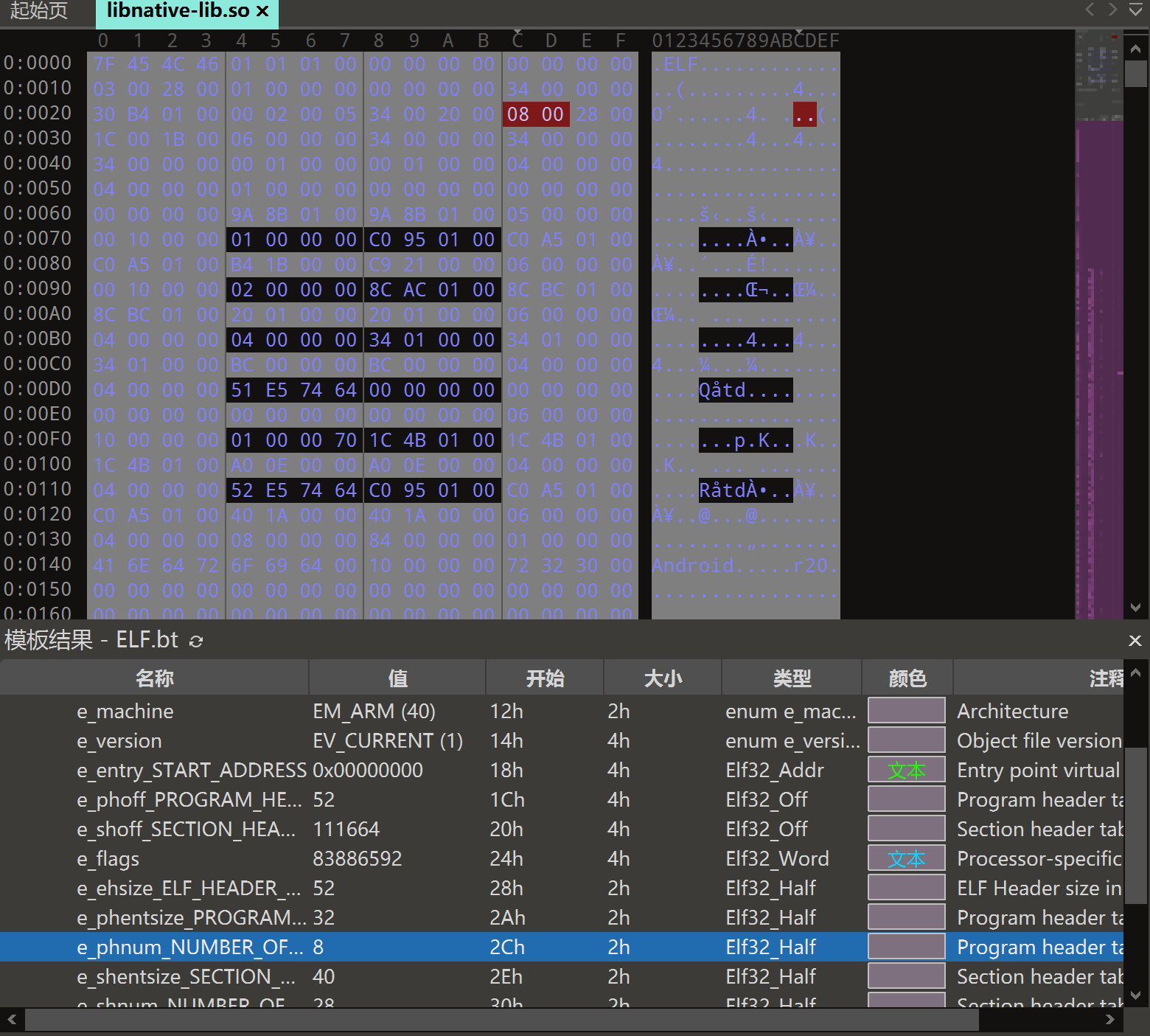
程序头表是一个Elf_Phdr类型的结构数组,定义如下所示
typedef struct
{
Elf32_Word p_type; /* Segment type */
Elf32_Off p_offset; /* Segment file offset */
Elf32_Addr p_vaddr; /* Segment virtual address */
Elf32_Addr p_paddr; /* Segment physical address */
Elf32_Word p_filesz; /* Segment size in file */
Elf32_Word p_memsz; /* Segment size in memory */
Elf32_Word p_flags; /* Segment flags */
Elf32_Word p_align; /* Segment alignment */
} Elf32_Phdr;
该for循环遍历程序头表,如果Elf32_Phdr.p_type为PT_DYNAMIC(2),则结束循环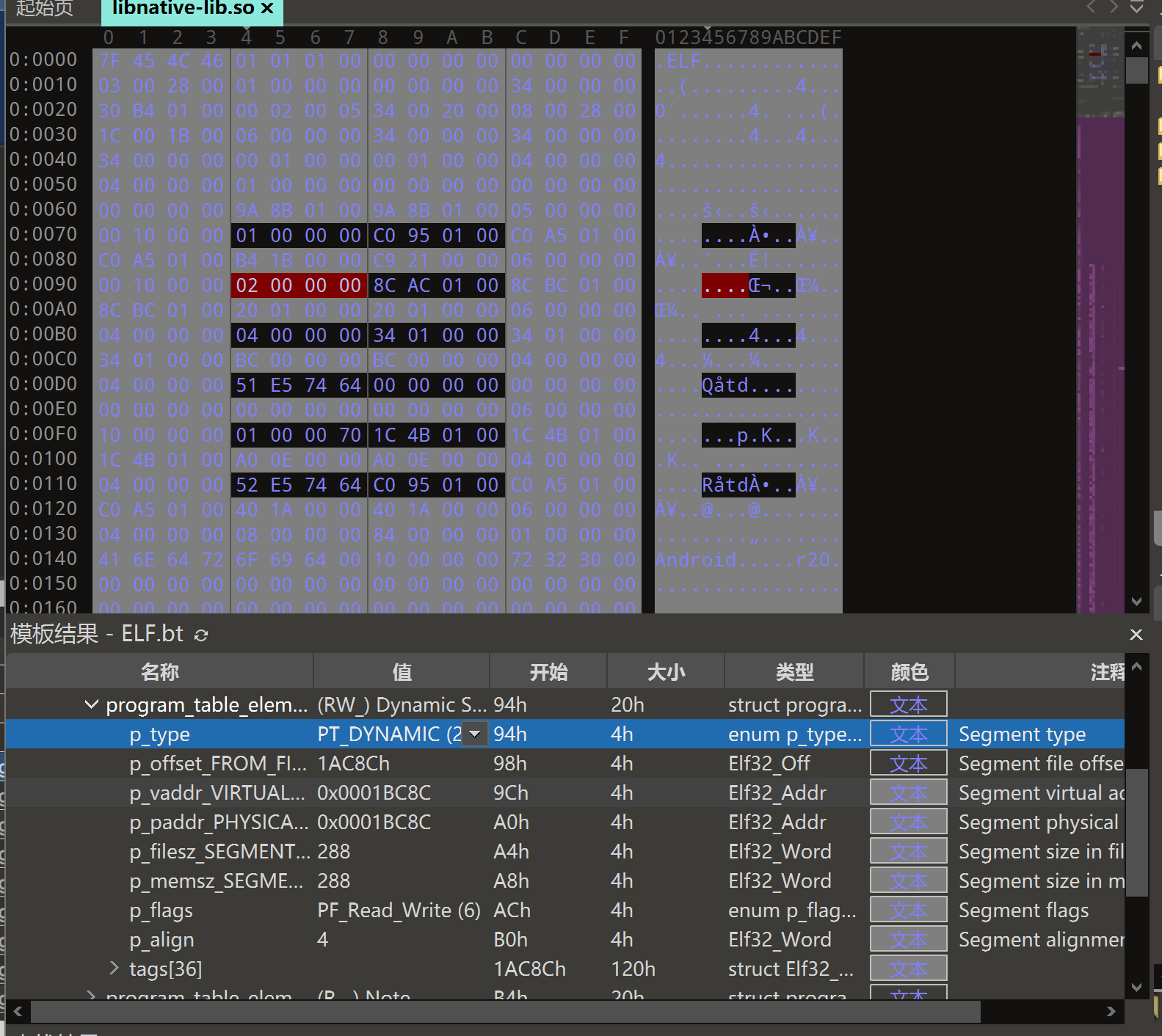
其实就是找到.dynamic段,该段主要与动态链接的整个过程有关,保存的是与动态链接相关信息,主要用于寻找与动态链接相关的其他节(.dynsym .dynstr .hash等节)。
如图所示
第43到66行的for循环里面,拿到了.dynsym、.dynstr、.hash等section的地址。.dynamic段的结构体定义如下:
typedef struct {
Elf32_Sword d_tag; // 动态段标签,标识这一项的类型(如 DT_NEEDED, DT_SYMTAB 等)
union {
Elf32_Word d_val; // 整数值(用于 DT_FLAGS 等)
Elf32_Addr d_ptr; // 地址值(用于 DT_STRTAB, DT_SYMTAB 等)
} d_un;
} Elf32_Dyn;
d_tag 值 |
ELF 宏 | 从哪里来 | 指向段 |
|---|---|---|---|
6 |
DT_SYMTAB |
*v11 |
.dynsym(动态符号表) |
5 |
DT_STRTAB |
*v11 |
.dynstr(动态字符串表) |
4 |
DT_HASH |
*v11 |
.hash(哈希表) |
常见的d_tag值
| 宏定义名 | 值 | 含义 |
|---|---|---|
DT_NULL |
0 | 结束标志 |
DT_NEEDED |
1 | 所依赖的共享库(字符串偏移) |
DT_PLTRELSZ |
2 | .rel.plt 段大小(或 .rela.plt) |
DT_PLTGOT |
3 | .got.plt 表地址 |
DT_HASH |
4 | 符号哈希表地址(老 ELF 哈希) |
DT_STRTAB |
5 | 字符串表地址(通常是 .dynstr) |
DT_SYMTAB |
6 | 符号表地址(通常是 .dynsym) |
DT_RELA |
7 | .rela.dyn 段地址(如使用 RELA) |
DT_RELASZ |
8 | .rela.dyn 段大小 |
DT_RELAENT |
9 | .rela 表项大小 |
DT_STRSZ |
10 | 字符串表大小 |
DT_SYMENT |
11 | 符号表项大小 |
DT_INIT |
12 | 初始化函数地址(如 _init) |
DT_FINI |
13 | 析构函数地址(如 _fini) |
DT_SONAME |
14 | DT_STRTAB 中的共享库名偏移 |
DT_RPATH |
15 | 链接器搜索路径(已弃用) |
DT_FLAGS |
30 | 标志位(ELF 标准的一些属性) |
.dynsym区节包含了动态链接符号表,符号表定义如下
typedef struct
{
Elf32_Word st_name; //函数符号在字符串表中的索引 .dynstr_offset + st_name就是函数符号的具体位置
Elf32_Addr st_value; //函数代码实现的位置地址
Elf32_Word st_size; //函数代码的长度
unsigned char st_info;
unsigned char st_other;
Elf32_Half st_shndx;
} Elf32_Sym;
第73行获取到hash表,hash表结构组织如下所示
-------------------------------
nbucket
-------------------------------
nchain
-------------------------------
bucket[0]
-------------------------------
...
-------------------------------
bucket[nbucket-1]
-------------------------------
chain[0]
-------------------------------
...
-------------------------------
chain[nchain-1]
-------------------------------
每个元素由Elf32_Word(大小为4个字节)对象组成,然后我们使用010editor看看hash表,这里nbucket=0x107,nchain=0x1B1,一共有(0x107 + 0x1B1 + 2) * 4 = 2792字节大小,如下所示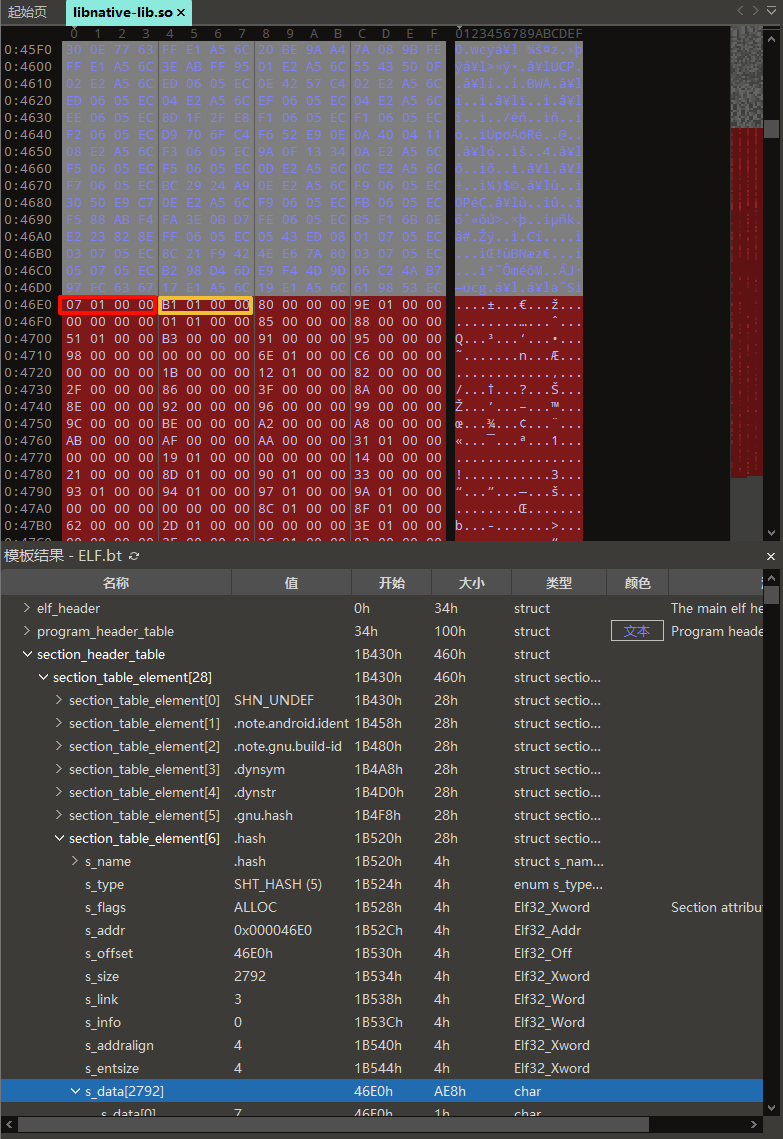
第74行使用hash函数(sub_92D6)计算符号的hash值,ELF的哈希函数是公开的,编译运行得到其hash值为0x766f8
#include <stdio.h>
int main(void){
const char *_name = "ooxx";
const unsigned char *name = (const unsigned char *) _name;
unsigned h = 0, g;
while(*name) {
h = (h << 4) + *name++;
g = h & 0xf0000000;
h ^= g;
h ^= g >> 24;
}
printf("%x\n",h); //0x766f8
return h;
}
第76到85行就是根据hash值与nbucket取模作为bucket链的索引,bucket[hash % nbucket]的值作为.dynsym的索引获得动态链接符号表(Elf32_Sym),从符号表的st_name找到.dynstr中对应的字符串与函数名相比较,若不等,则根据bucket[hash % nbucket]的值X作为chain链的索引,chain[X]的值重新获取一个动态链接符号表,拿到字符串索引后获取.dynstr中对应的字符串与函数名相比较,若再不等,继续根据chain[X]的值Y作为chain链的索引,chain[Y]的值重新获取一个动态链接符号表,直到找到或者chain终止为止。代码实现如下
for(i = bucket[funHash % nbucket]; i != 0; i = chain[i]){
if(strcmp(dynstr + (dynsym + i)->st_name, funcName) == 0){
flag = 0;
break;
}
}
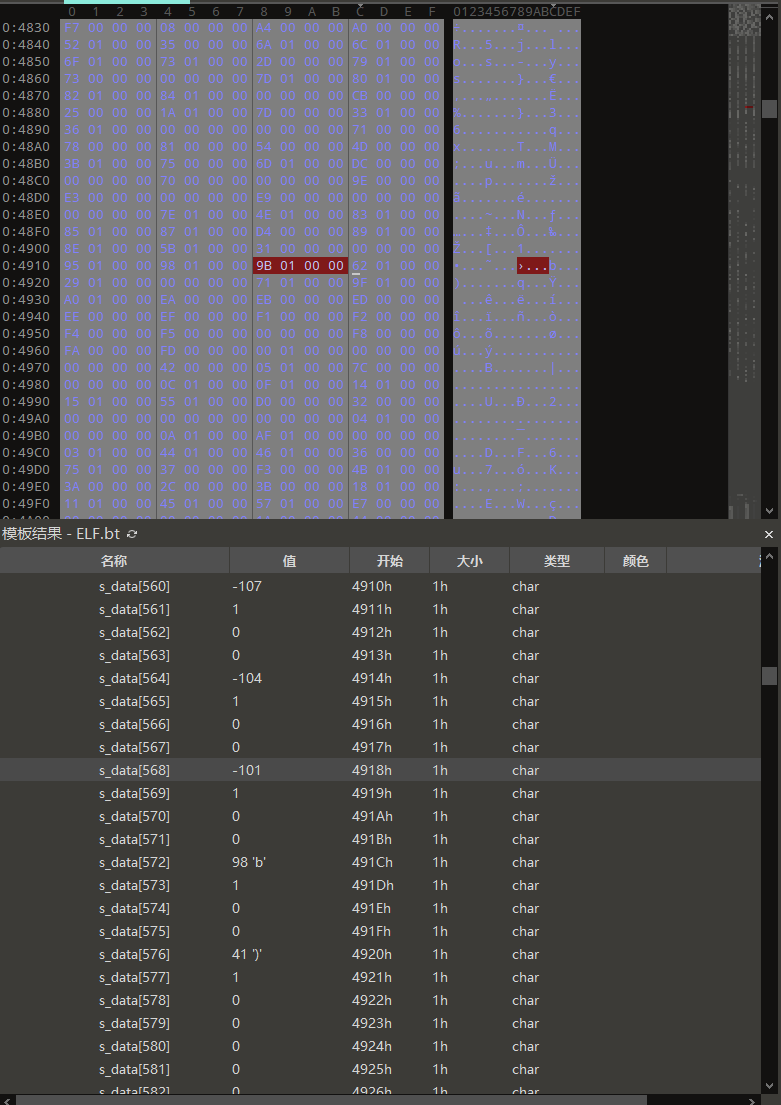
看上去还是比较绕,我们在010 Editor里面手动计算一下,函数Hash值在74行代码中已经计算得到0x766F8,nbucket=0x107,mod为hash % nbucket = 140,因为hash表的前两个元素是nbucket和nchain,每个元素是Elf32_Word类型,大小为4,所以bucket[hash % nbucket]是第(140 + 2) * 4 = 568号字节,其值为0x19B
.dynstr字符串表的offset等于0x1D00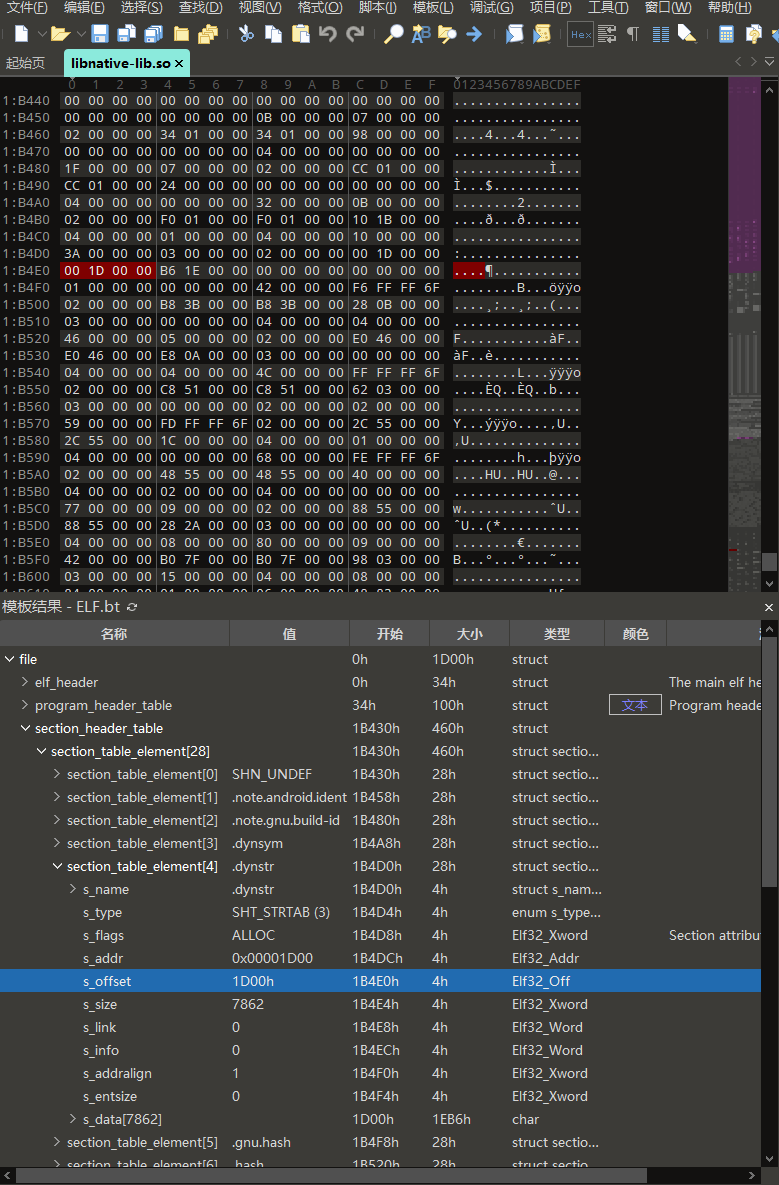
st_name为索引的字符串位置则等于0x1D00 + 0x1617 = 0x3317,对应字符串”_ZTIPn”,与ooxx不等。所以需要计算chain[0x19B]的值。先计算chain的起始位置为(nbucket + 2) * 4,nbucket = 0x107,所以chain的起始位置为1060号字节,0x19B十进制为411,那chain链的411索引对应的字节应该是1060 + 411 * 4 = 2704号字节,值为0x5D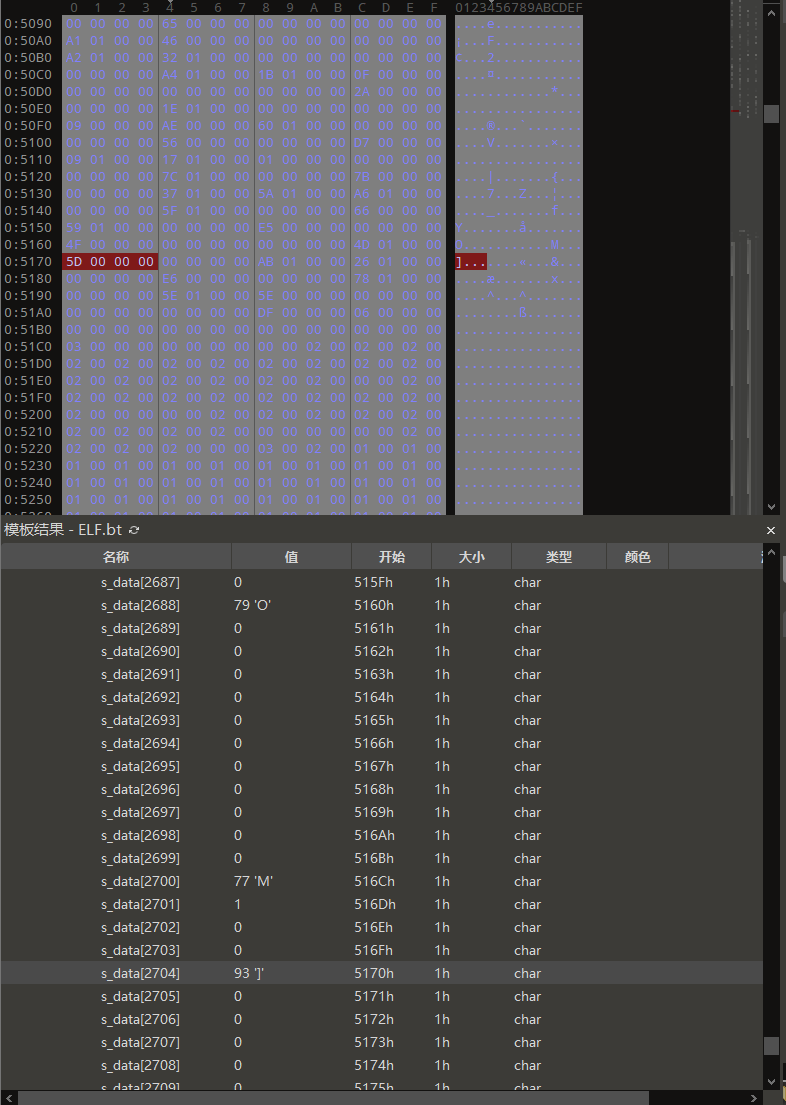
对应.dynsym动态链接符号表的位置为0x5D * 16 = 1488号字节,st_name = 0x214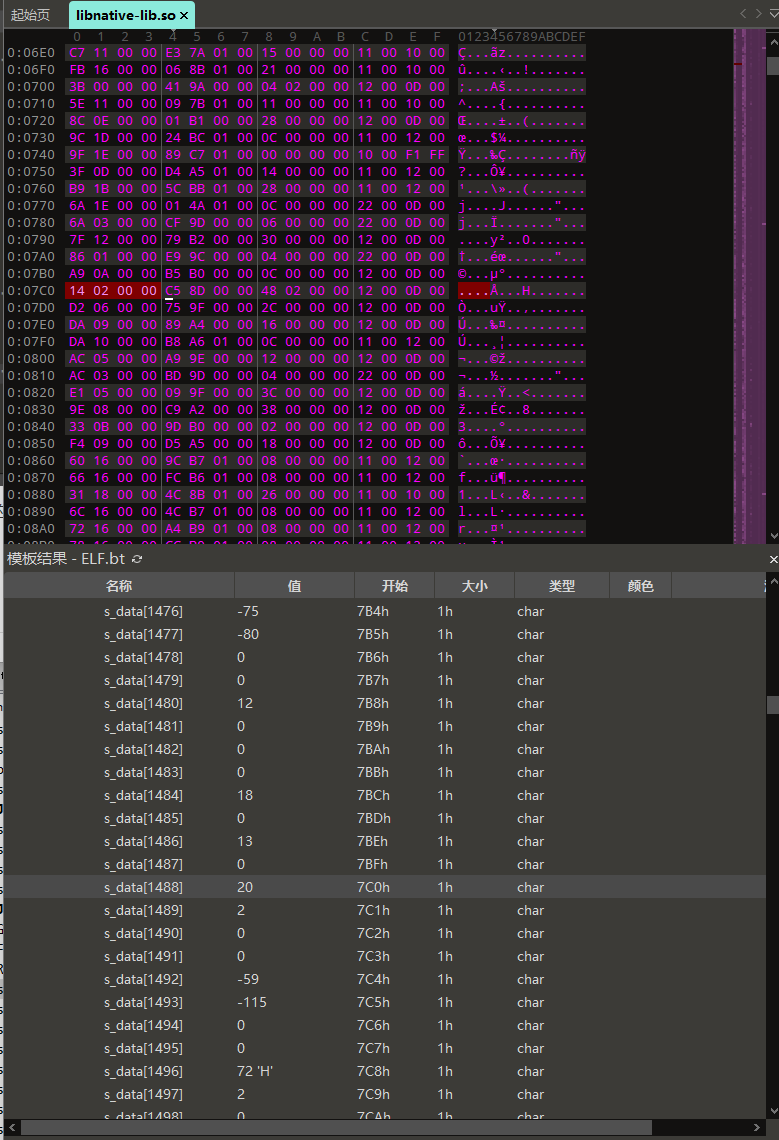
对应的字符串地址为0x1D00 + 0x214 = 0x1F14,字符串值为”ooxx”,是我们需要查找的符号。结合上图,则可知Elf32_Sym对象的st_value = 0x8DC5,st_size = 0x248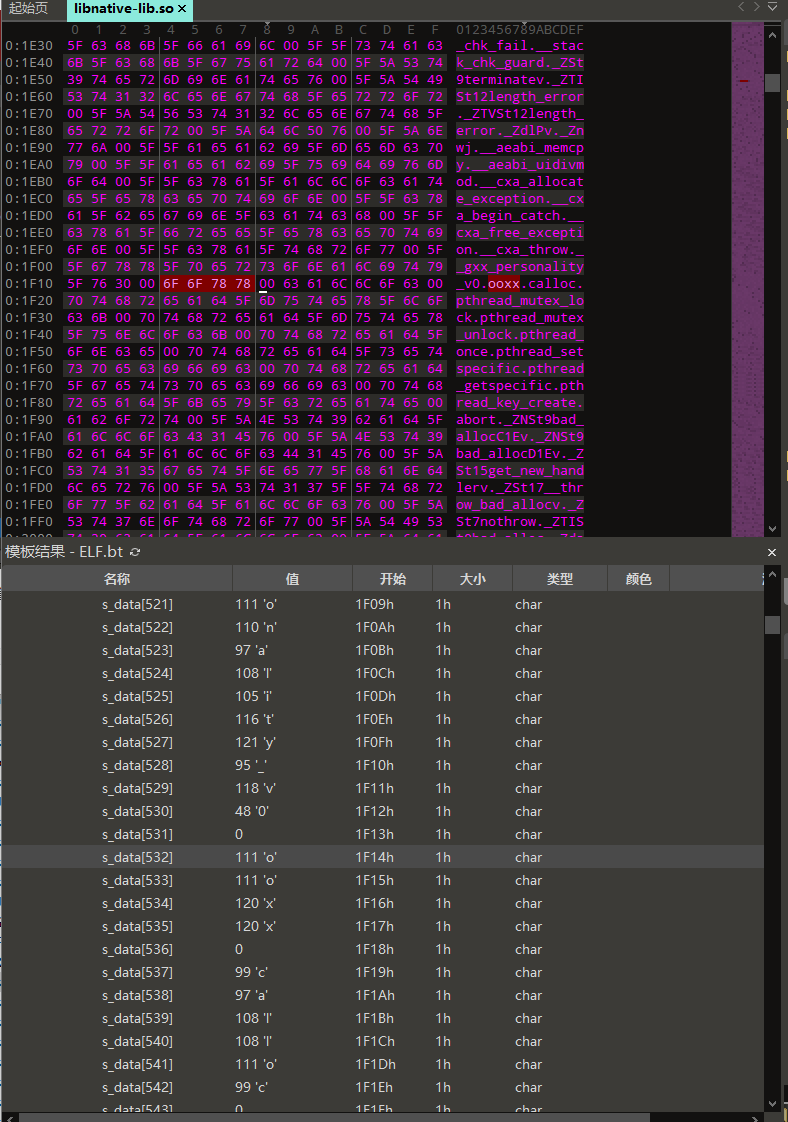
2.5函数解密
上述sub_8B90函数最后返回0,所以在sub_8930函数的第19行if判断结果为false,然后开始执行第23行的else逻辑。具体分析如下

第26行的v10变量,伪代码中没有对该变量进行赋值,双击v9和v10发现他们在堆栈是连续的,其实对应于sub_8B90函数最后的st_value和st_size赋值给v9指针,所以v10变量就是st_size
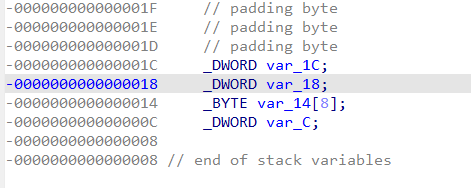
第36行,这里的i表示加(解)密代码的起始地址,通过遍历地址然后解引与byte_1C180数组中的值进行异或运算得到明文,这里的byte_1C180数组就相当于是解密密钥。查看byte_1C180,发现其定义在.bss段
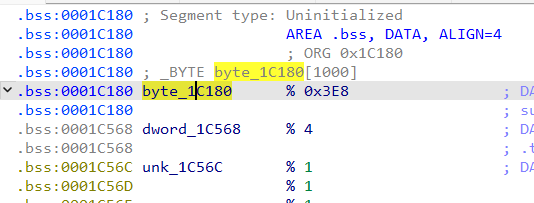
bss段通常是用来存放程序中未初始化的全局变量的一块内存区域,静态分析的情况下,无法查看其值,比较方便的方法是程序运行起来后,直接将对应内存中的数据dump下来,那就需要知道byte_1C180数组在内存中的起始地址和大小。
起始地址比较容易计算,等于libnative-lib.so在内存中的基地址 + 0x1C180。通过分析第35行的for循环,可知数组的大小就等于v4-v5,即(v8 + v9 + v10 - 61) - (v8 + v9 + 59) = v10 - 61 - 59 = st_size - 61 - 59 = 0x248 - 61 - 59 = 464。根据上述信息,直接使用objection dump内存,先使用指令
objection -d -g com.kanxue.test explore
以调试模式连接到包名为com.kanxue.test的应用,注入后进入交互式命令环境,然后使用指令
memory list modules
查看libnative-lib.so在内存中的基地址,然后dump出内存数据:
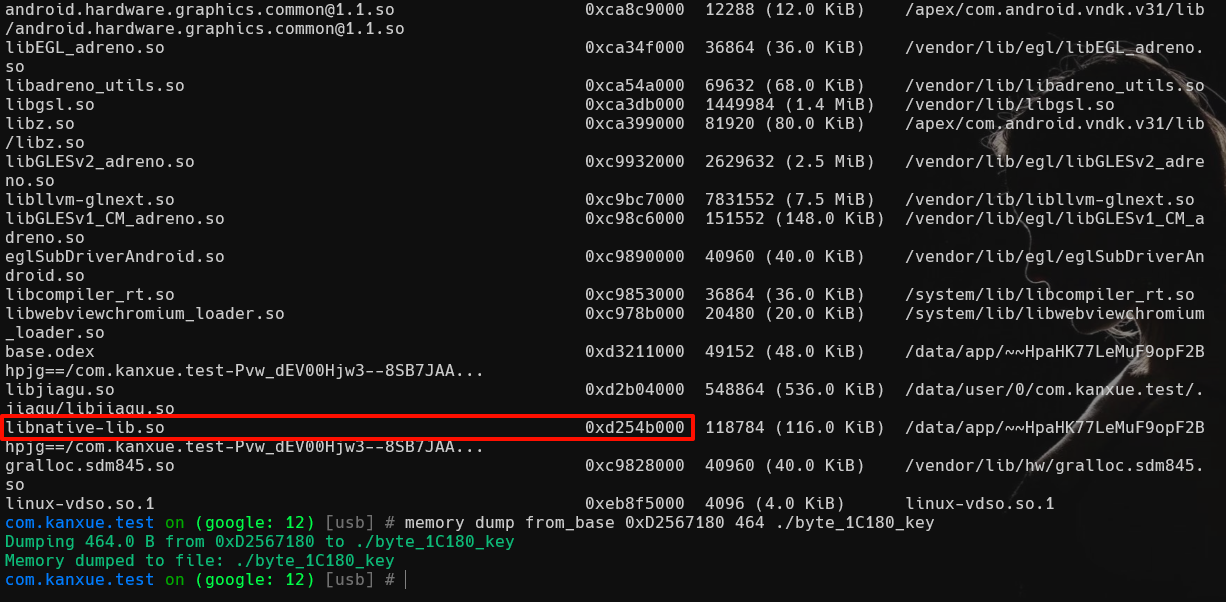
然后010打开dump下来的文件
结合伪代码逻辑,idapython脚本如下
key = [0x00, 0x01, 0x02, 0x03, 0x04, 0x05, 0x06, 0x07, 0x08, 0x09, 0x0A, 0x0B, 0x0C, 0x0D, 0x0E, 0x0F,
0x10, 0x11, 0x12, 0x13, 0x14, 0x15, 0x16, 0x17, 0x18, 0x19, 0x1A, 0x1B, 0x1C, 0x1D, 0x1E, 0x1F,
0x20, 0x21, 0x22, 0x23, 0x24, 0x25, 0x26, 0x27, 0x28, 0x29, 0x2A, 0x2B, 0x2C, 0x2D, 0x2E, 0x2F,
0x30, 0x31, 0x32, 0x33, 0x34, 0x35, 0x36, 0x37, 0x38, 0x39, 0x3A, 0x3B, 0x3C, 0x3D, 0x3E, 0x3F,
0x40, 0x41, 0x42, 0x43, 0x44, 0x45, 0x46, 0x47, 0x48, 0x49, 0x4A, 0x4B, 0x4C, 0x4D, 0x4E, 0x4F,
0x50, 0x51, 0x52, 0x53, 0x54, 0x55, 0x56, 0x57, 0x58, 0x59, 0x5A, 0x5B, 0x5C, 0x5D, 0x5E, 0x5F,
0x60, 0x61, 0x62, 0x63, 0x64, 0x65, 0x66, 0x67, 0x68, 0x69, 0x6A, 0x6B, 0x6C, 0x6D, 0x6E, 0x6F,
0x70, 0x71, 0x72, 0x73, 0x74, 0x75, 0x76, 0x77, 0x78, 0x79, 0x7A, 0x7B, 0x7C, 0x7D, 0x7E, 0x7F,
0x80, 0x81, 0x82, 0x83, 0x84, 0x85, 0x86, 0x87, 0x88, 0x89, 0x8A, 0x8B, 0x8C, 0x8D, 0x8E, 0x8F,
0x90, 0x91, 0x92, 0x93, 0x94, 0x95, 0x96, 0x97, 0x98, 0x99, 0x9A, 0x9B, 0x9C, 0x9D, 0x9E, 0x9F,
0xA0, 0xA1, 0xA2, 0xA3, 0xA4, 0xA5, 0xA6, 0xA7, 0xA8, 0xA9, 0xAA, 0xAB, 0xAC, 0xAD, 0xAE, 0xAF,
0xB0, 0xB1, 0xB2, 0xB3, 0xB4, 0xB5, 0xB6, 0xB7, 0xB8, 0xB9, 0xBA, 0xBB, 0xBC, 0xBD, 0xBE, 0xBF,
0xC0, 0xC1, 0xC2, 0xC3, 0xC4, 0xC5, 0xC6, 0xC7, 0xC8, 0xC9, 0xCA, 0xCB, 0xCC, 0xCD, 0xCE, 0xCF,
0xD0, 0xD1, 0xD2, 0xD3, 0xD4, 0xD5, 0xD6, 0xD7, 0xD8, 0xD9, 0xDA, 0xDB, 0xDC, 0xDD, 0xDE, 0xDF,
0xE0, 0xE1, 0xE2, 0xE3, 0xE4, 0xE5, 0xE6, 0xE7, 0xE8, 0xE9, 0xEA, 0xEB, 0xEC, 0xED, 0xEE, 0xEF,
0xF0, 0xF1, 0xF2, 0xF3, 0xF4, 0xF5, 0xF6, 0xF7, 0xF8, 0xF9, 0xFA, 0xFB, 0xFC, 0xFD, 0xFE, 0xFF,
0x00, 0x01, 0x02, 0x03, 0x04, 0x05, 0x06, 0x07, 0x08, 0x09, 0x0A, 0x0B, 0x0C, 0x0D, 0x0E, 0x0F,
0x10, 0x11, 0x12, 0x13, 0x14, 0x15, 0x16, 0x17, 0x18, 0x19, 0x1A, 0x1B, 0x1C, 0x1D, 0x1E, 0x1F,
0x20, 0x21, 0x22, 0x23, 0x24, 0x25, 0x26, 0x27, 0x28, 0x29, 0x2A, 0x2B, 0x2C, 0x2D, 0x2E, 0x2F,
0x30, 0x31, 0x32, 0x33, 0x34, 0x35, 0x36, 0x37, 0x38, 0x39, 0x3A, 0x3B, 0x3C, 0x3D, 0x3E, 0x3F,
0x40, 0x41, 0x42, 0x43, 0x44, 0x45, 0x46, 0x47, 0x48, 0x49, 0x4A, 0x4B, 0x4C, 0x4D, 0x4E, 0x4F,
0x50, 0x51, 0x52, 0x53, 0x54, 0x55, 0x56, 0x57, 0x58, 0x59, 0x5A, 0x5B, 0x5C, 0x5D, 0x5E, 0x5F,
0x60, 0x61, 0x62, 0x63, 0x64, 0x65, 0x66, 0x67, 0x68, 0x69, 0x6A, 0x6B, 0x6C, 0x6D, 0x6E, 0x6F,
0x70, 0x71, 0x72, 0x73, 0x74, 0x75, 0x76, 0x77, 0x78, 0x79, 0x7A, 0x7B, 0x7C, 0x7D, 0x7E, 0x7F,
0x80, 0x81, 0x82, 0x83, 0x84, 0x85, 0x86, 0x87, 0x88, 0x89, 0x8A, 0x8B, 0x8C, 0x8D, 0x8E, 0x8F,
0x90, 0x91, 0x92, 0x93, 0x94, 0x95, 0x96, 0x97, 0x98, 0x99, 0x9A, 0x9B, 0x9C, 0x9D, 0x9E, 0x9F,
0xA0, 0xA1, 0xA2, 0xA3, 0xA4, 0xA5, 0xA6, 0xA7, 0xA8, 0xA9, 0xAA, 0xAB, 0xAC, 0xAD, 0xAE, 0xAF,
0xB0, 0xB1, 0xB2, 0xB3, 0xB4, 0xB5, 0xB6, 0xB7, 0xB8, 0xB9, 0xBA, 0xBB, 0xBC, 0xBD, 0xBE, 0xBF,
0xC0, 0xC1, 0xC2, 0xC3, 0xC4, 0xC5, 0xC6, 0xC7, 0xC8, 0xC9, 0xCA, 0xCB, 0xCC, 0xCD, 0xCE, 0xCF]
def patchFunc(addr,size,key):
for i in range(size):
# 从addr处读取1个字节的内容
byte = get_bytes(addr + i, 1)
# 异或运算解密
decodeBuf = ord(byte) ^ key[i]
print("i: %d, addr: %s, bytes_hex: %s, decode_bytes_hex: %s" % (i,hex(addr + i),hex(ord(byte)),hex(decodeBuf)))
# 将addr地址处patch成decodeBuf的内容
patch_byte(addr + i, decodeBuf)
patchFunc(0x8e00,464,key)
ida直接运行脚本之后,发现ooxx函数的垃圾指令消失了。但是查看汇编会发现还是有不少指令没有正确识别
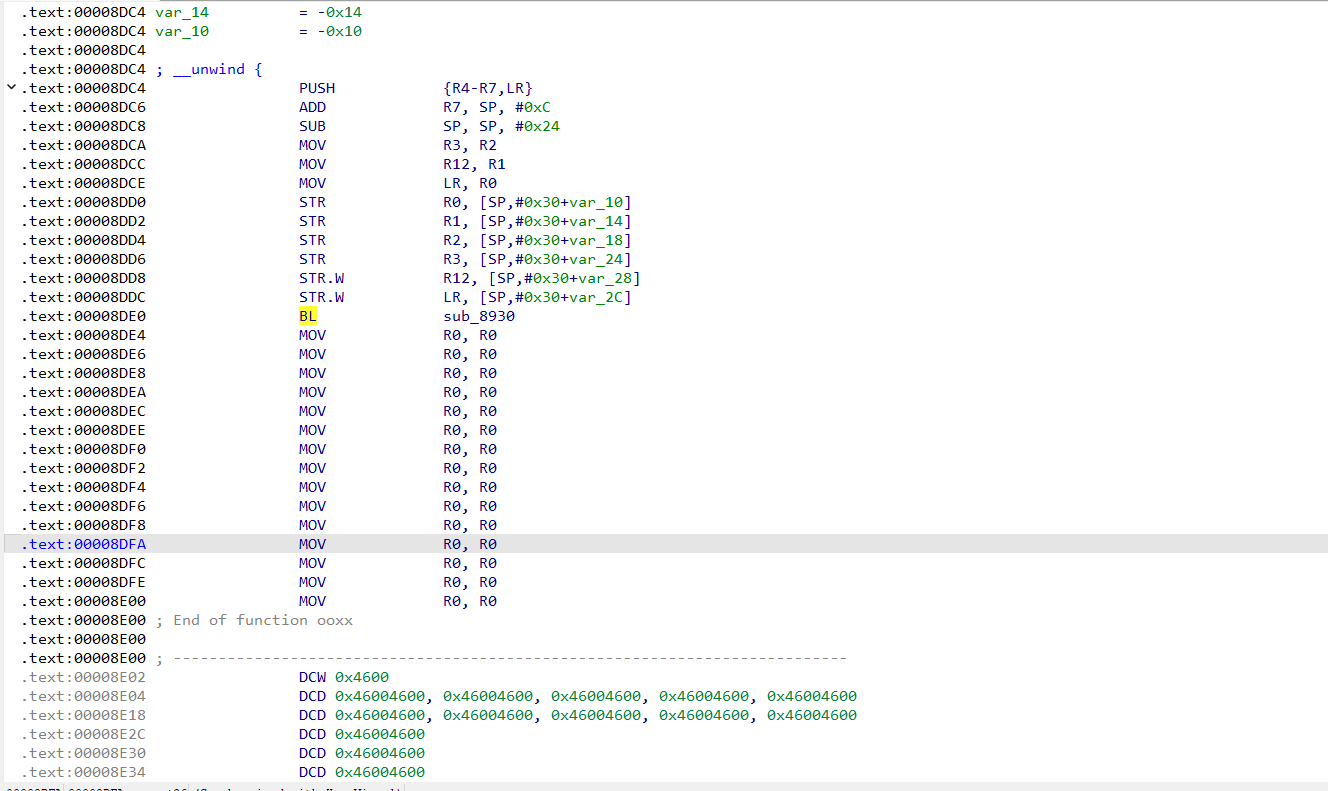
手动处理一下,在指令的最后方按一下E,申明一下函数结尾,就可以F5正常反编译了
bool __fastcall ooxx(int a1, int a2, int a3)
{
char *s2; // [sp+10h] [bp-20h]
bool v5; // [sp+17h] [bp-19h]
sub_8930();
v5 = 0;
s2 = (char *)sub_900C(a1, a3, 0);
if ( s2 )
v5 = strcmp(s1_, s2) == 0;
sub_8930();
return v5;
}
逻辑就是将输入和kanxuetest(在前面异或解密得到的)进行比对。验证一下
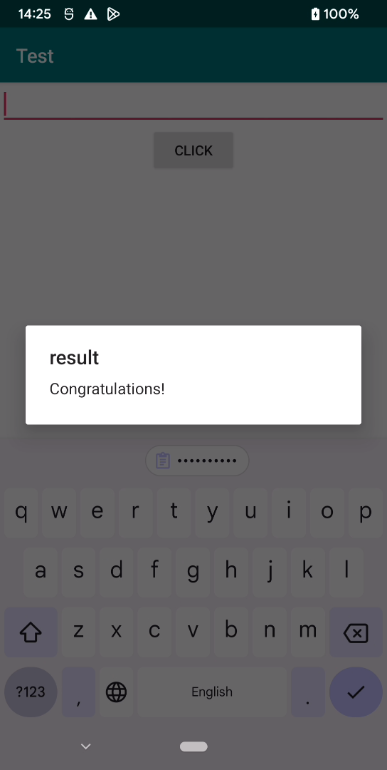
最后附上附件
通过网盘分享的文件:记一次APK分析.zip
链接: https://pan.baidu.com/s/10xbShpIBcifkbQtI5KVoqg?pwd=81xp 提取码: 81xp
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 1621925986@qq.com

