TEXSAWCTF 2025
xorer
ida打开看到就是一个xor
void __cdecl check_password(char *input)
{
int v1; // eax
unsigned __int8 key[12]; // [esp+Ch] [ebp-1Ch] BYREF
int len; // [esp+18h] [ebp-10h]
int i; // [esp+1Ch] [ebp-Ch]
qmemcpy(key, "藭漾淹桗蒙懧", 6);
len = strlen(input);
for ( i = 0; i <= 7; ++i )
{
v1 = input[i];
LOBYTE(v1) = v1 ^ 0xA5;
if ( v1 != key[i] )
{
puts("Wrong password!");
return;
}
}
printf("Correct! Here's your flag: texsaw{%s}\n", input);
}
数据提取出来直接异或
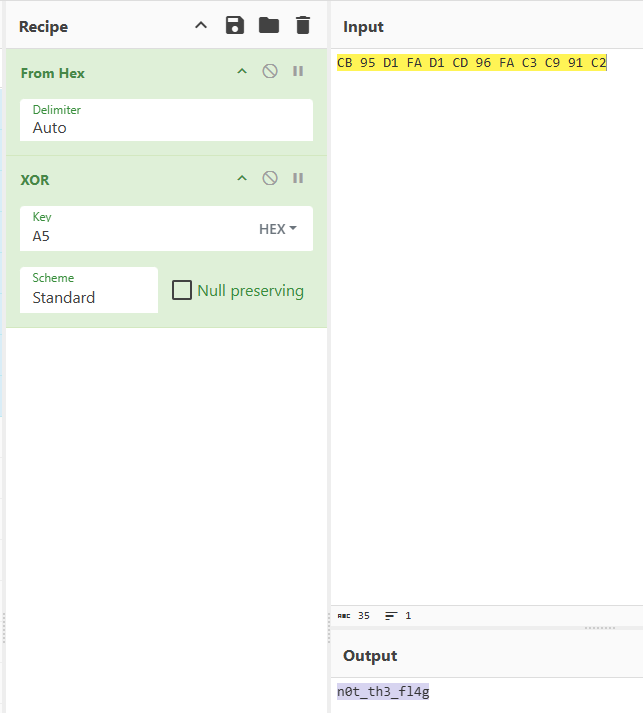
texsaw{n0t_th3_fl4g}
Too Early 4 Me
ida打开分析,直接有decode的逻辑,改一下EIP,改到decode函数的地址,直接程序自己输出了
unsigned __int64 decode_flag()
{
int i; // [rsp+8h] [rbp-118h]
unsigned int j; // [rsp+Ch] [rbp-114h]
char v3[264]; // [rsp+10h] [rbp-110h]
unsigned __int64 v4; // [rsp+118h] [rbp-8h]
v4 = __readfsqword(0x28u);
for ( i = 0; i <= 255; ++i )
v3[sbox[i]] = i;
printf("Decoded flag: ");
for ( j = 0; j <= 33; ++j )
putchar(v3[encoded_flag[j]]);
putchar(10);
return v4 - __readfsqword(0x28u);
}

texsaw{how_signalicious_much_swag}
ez rev
一道OCaml逆向。
ida打开分析,进入main函数,看到
int __fastcall __noreturn main(int argc, const char **argv, const char **envp)
{
caml_main((char_os **)argv);
caml_do_exit(0);
}
直接跟进caml_main函数,然后再跟进caml_startup_common函数
这是OCaml运行时系统的启动函数,负责初始化OCaml虚拟机环境,调用初始化OCaml域,解析运行时参数等等。
调用caml_start_program启动OCaml主程序

跟进
__int64 __fastcall caml_start_program(_QWORD *a1)
{
__int64 v1; // r15
__int64 result; // rax
_QWORD v3[2]; // [rsp-28h] [rbp-68h] BYREF
__int64 v4; // [rsp-18h] [rbp-58h]
__int64 v5; // [rsp-10h] [rbp-50h]
__int64 v6; // [rsp-8h] [rbp-48h]
v6 = a1[28];
v5 = a1[27];
v4 = a1[26];
v1 = a1[1];
v3[1] = sub_846FF;
v3[0] = a1[2];
a1[2] = v3;
result = caml_startup__code_begin();
a1[2] = v3[0];
a1[1] = v1;
a1[26] = v4;
a1[27] = v5;
a1[28] = v6;
return result;
}
这是OCaml运行时系统中启动OCaml主程序的函数,它负责设置执行环境并跳转到OCaml代码的入口点。
跟进caml_startup__code_begin函数
__int64 caml_startup__code_begin()
{
camlCamlinternalFormatBasics__entry();
++caml_globals_inited;
camlCamlinternalAtomic__entry();
++caml_globals_inited;
camlStdlib__entry();
++caml_globals_inited;
camlStdlib__Sys__entry();
++caml_globals_inited;
camlStdlib__Obj__entry();
++caml_globals_inited;
camlCamlinternalLazy__entry();
++caml_globals_inited;
camlStdlib__Lazy__entry();
++caml_globals_inited;
camlStdlib__Seq__entry();
++caml_globals_inited;
camlStdlib__Char__entry();
++caml_globals_inited;
camlStdlib__Uchar__entry();
++caml_globals_inited;
camlStdlib__List__entry();
++caml_globals_inited;
camlStdlib__Int__entry();
++caml_globals_inited;
camlStdlib__Bytes__entry();
++caml_globals_inited;
camlStdlib__String__entry();
++caml_globals_inited;
camlStdlib__Buffer__entry();
++caml_globals_inited;
camlCamlinternalFormat__entry();
++caml_globals_inited;
camlStdlib__Printf__entry();
++caml_globals_inited;
camlEasy_rev__entry();
++caml_globals_inited;
camlStd_exit__entry();
++caml_globals_inited;
return 1LL;
}
这是OCaml程序启动时的初始化函数,负责初始化OCaml标准库和用户模块的入口点。
**camlEasy_rev__entry()**模块应该就是出题人自定义的模块
void __cdecl camlEasy_rev__entry()
{
__int64 v0; // rax
__int64 v1; // rax
__int64 v2; // rax
void (**v3)(void); // rax
camlEasy_rev[0] = &camlEasy_rev__10;
camlEasy_rev[1] = &camlEasy_rev__20;
camlEasy_rev[2] = &camlEasy_rev__30;
camlStdlib___40_198();
camlStdlib___40_198();
camlEasy_rev[3] = v0;
camlEasy_rev[4] = &camlEasy_rev__38;
camlStdlib__List__map_482();
camlEasy_rev[5] = v1;
camlStdlib__List__fold_left_521();
camlEasy_rev[6] = v2;
camlStdlib__Printf__fprintf_422();
(*v3)();
}
**camlStdlib___40_198()的作用是构造链表。然后呢,这里的camlStdlibListfold_left_521()**函数需要修改一下函数声明,然后F5重新反编译一下,
void __cdecl camlEasy_rev__entry()
{
__int64 v0; // rsi
__int64 v1; // rax
__int64 v2; // rax
__int64 v3; // rdx
__int64 v4; // rax
void (**v5)(void); // rax
camlEasy_rev[0] = &camlEasy_rev__10;
camlEasy_rev[1] = &camlEasy_rev__20;
camlEasy_rev[2] = &camlEasy_rev__30;
camlStdlib___40_198();
camlStdlib___40_198();
camlEasy_rev[3] = v1;
camlEasy_rev[4] = &camlEasy_rev__38;
camlStdlib__List__map_482();
camlEasy_rev[5] = v2;
camlStdlib__List__fold_left_521(camlEasy_rev[5], v0, v3);
camlEasy_rev[6] = v4;
camlStdlib__Printf__fprintf_422();
(*v5)();
}
然后动调,camlStdlibListfold_left_521函数的第二个参数才是本来的操作

这段应该是实现除法的功能。然后**camlStdlibPrintffprintf_422()**函数就会输出
sum of all flag elements: 2836。
这些就是对应数据,写个脚本扣出来
import idautils
import idc
import idaapi
def get_first_qword(addr):
"""读取地址处的第一个 QWORD 值"""
return idc.get_qword(addr)
def main():
print("[*] Extracting camlEasy_rev__1 to camlEasy_rev__30 values...")
results = []
# 遍历符号 camlEasy_rev__1 到 camlEasy_rev__30
for i in range(1, 31): # 1~30
symbol_name = f"camlEasy_rev__{i}"
symbol_addr = idc.get_name_ea_simple(symbol_name)
# 验证符号是否存在
if symbol_addr == idaapi.BADADDR:
print(f"[!] Symbol {symbol_name} not found!")
continue
# 读取第一个 QWORD 值(假设链表节点结构为 [QWORD data, QWORD next])
first_qword = get_first_qword(symbol_addr)
results.append((symbol_name, first_qword))
# 输出结果
for name, value in results:
print(f"{name}: 0x{value:X}")
if __name__ == "__main__":
main()
拿到数据,可以开始写爆破脚本了,因为具体不知道出几,然后flag字符的和就是运行程序输出的那个值,2836。但是还有一个问题,就是flag字符的顺序。
分析链表构造函数逻辑可知,采用的是递归反向构造技术,并且将flag平均分成三部分,也可以从节点的指针进行分析

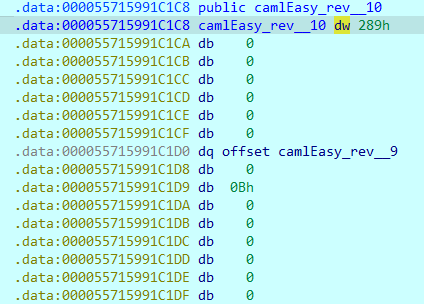
这是一个完整的节点,前半部分是本节点的值,后半部分是指向的下一个节点。如上图就是第十个节点的值是0x289,指向的下一个节点就是第九个节点。
然后我们按顺序处理好数据,然后写个脚本进行求解
enc = [ 0x2B9, 0x25F, 0x2D1, 0x2B3, 0x247, 0x2CB, 0x2E3, 0x247, 0x23B, 0x24D,
0x127, 0x2B9, 0x23B, 0x121, 0x265, 0x23B, 0x121, 0x253, 0x139, 0x28F,
0x289, 0x23B, 0x2AD, 0x133, 0x2C5, 0x133, 0x2AD, 0x2B3, 0x133, 0x2EF,]
for num in range(1, 100):
sum = 0
for i in enc:
sum += i // num
if sum == 2836:
print("flag: ", end="")
for j in enc:
print(chr(j // num), end="")
print()
print(f"divisor: {num}")
flag: texsaw{a_b1t_0f_0c4ml_r3v3rs3}
divisor: 6
Babies first ez Python4
下载下来附件是个.txt,打开来看到内容是混淆严重的python字节码
可以先写个脚本进行去除一下
import re
# 读取文件内容
with open("chal.txt", "r", encoding="utf-8") as f:
content = f.read()
# 匹配由 a 和 b 组成的、长度不少于 20 的连续串
pattern = r"(?:[ab]{20,})"
# 找到所有匹配项
matches = re.findall(pattern, content)
# 用于记录已经替换过的串,防止重复编号
seen = {}
counter = 1
# 替换函数
def replacer(match):
global counter
m = match.group(0)
if m not in seen:
label = f"obf_{counter:03d}"
seen[m] = label
counter += 1
return seen[m]
# 进行替换
new_content = re.sub(pattern, replacer, content)
# 将处理后的内容写入新文件
with open("cleaned_chal.txt", "w", encoding="utf-8") as f:
f.write(new_content)
然后代码前半部分,应该是常量的申明

然后这部分应该是类似于函数头和函数结尾?
再往下就是每个常量,或者说字符的由来
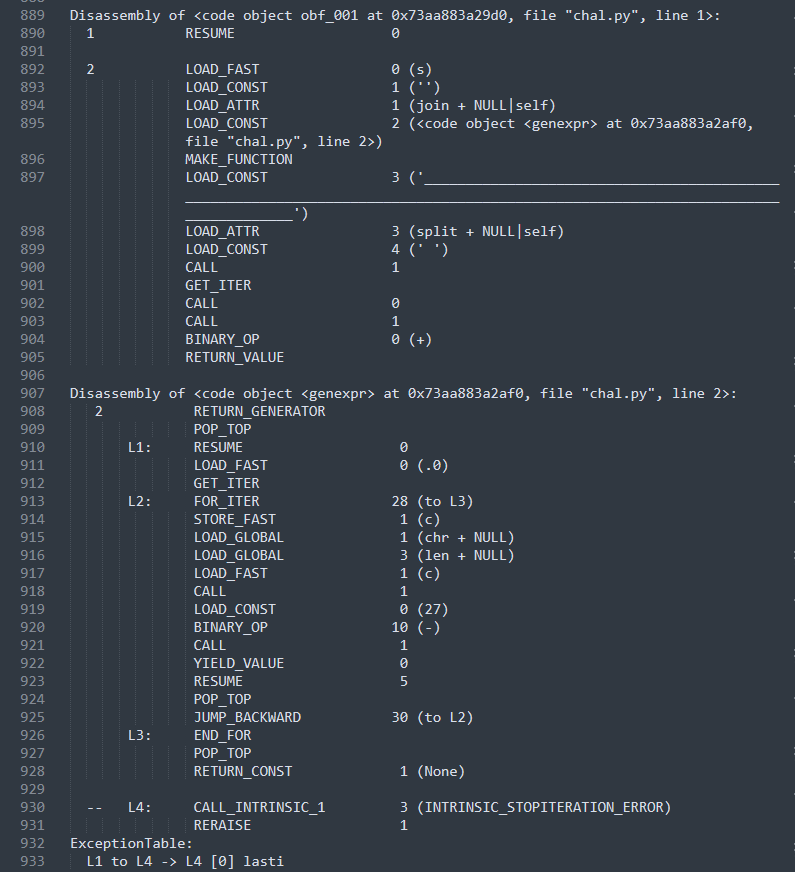
就是根据字符 ‘_’的长度,减27,然后转成字符,这里可以写哥脚本提出来
import re
def extract_from_disassembly(file_path, output_path):
with open(file_path, "r", encoding="utf-8") as f:
content = f.read()
# 匹配每段函数体:Disassembly of <code object obf_XXX ...> 到下一个 Disassembly 或文件末尾
pattern = r'Disassembly of <code object (obf_\d{3})[^>]*>:\n(.*?)(?=Disassembly of <code object|$)'
matches = re.findall(pattern, content, re.DOTALL)
results = []
for func_name, block_text in matches:
# 找到连续 30 个以上下划线
underscores = re.findall(r'_{30,}', block_text)
for us in underscores:
code = len(us) - 27
char = chr(code) if 0 <= code <= 127 else '?'
results.append(f"{func_name}: {char}")
# 保存到文件
with open(output_path, "w", encoding="utf-8") as f:
f.write('\n'.join(results))
print(f"✅ 已保存输出到: {output_path}")
print(f"共提取 {len(results)} 个字符。")
# 使用
if __name__ == "__main__":
input_file = "cleaned_chal.txt"
output_file = "underscore_ascii.txt"
extract_from_disassembly(input_file, output_file)
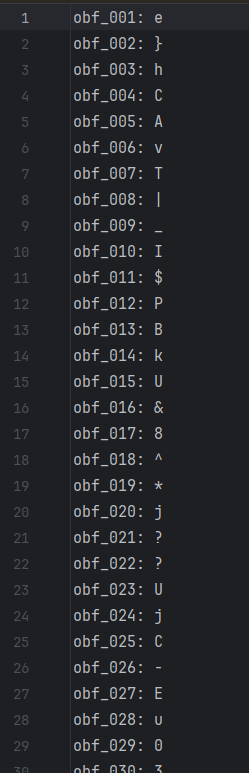
输出的内容就是每个字符和所对应的变量名(应该称之为变量名吗?)。然后继续分析
如果合在一起就是
e}hCAvT|_I$PBkU&8^*j??UjC-Eu03HQx{9h)fsr@b!Mbza
E@000SLOCDM@aZJ3}T^<&soW>K);b46)R^5Q~60j9WLpOKaR?X=B^blpE@}ScQbr&5eC;qC{uDh2&`o8byg;hY8jCT_f{2Y35input__import__base64b85encode__import__zlibcompressencodecencodeprintcorrect flag!
然后根据那一堆没去混淆的z_zzz_zzz来进行回车分割可以猜测就是调用了encode()方法,然后还用到了zlib.compress()和base64.b85encode(),
再往下
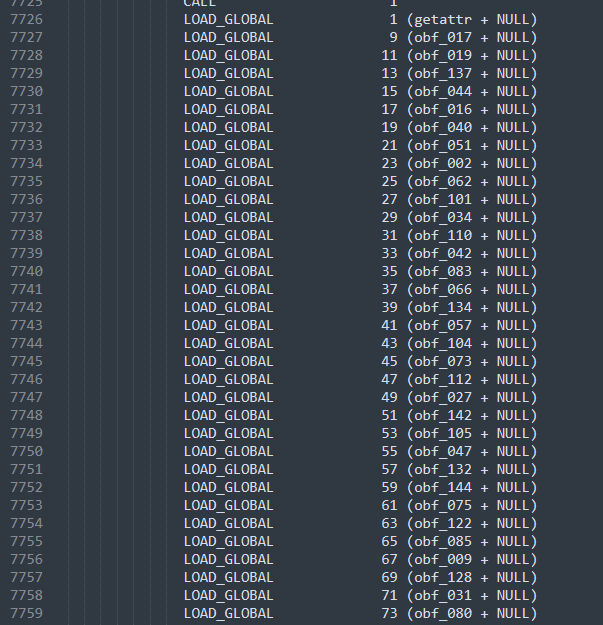
就是对密文的加载,根据这里加载的混淆名,可以得到完整的密文,
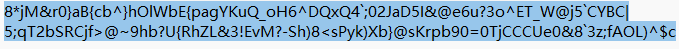
这里注意不能漏了最后一个’c’
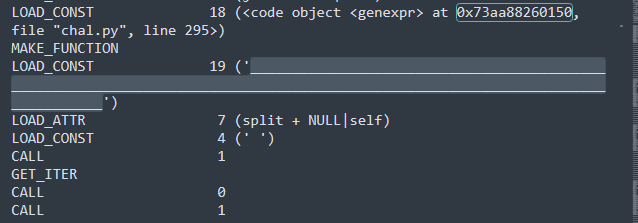
然后梳理完整的流程就是
调用了encode()方法,将字符串转换为字节序列 ->
使用zlib.compress()进行压缩->
使用base64.b85encode()对压缩后的数据进行base85编码->
然后就可以写脚本进行解密了
import base64
import zlib
encrypted_data = "8*jM&r0}aB{cb^}hOlWbE{pagYKuQ_oH6^DQxQ4`;02JaD5I&@e6u?3o^ET_W@j5`CYBC|5;qT2bSRCjf>@~9hb?U{RhZL&3!EvM?-Sh)8<sPyk)Xb}@sKrpb90=0TjCCCUe0&8`3z;fAOL)^$c"
encrypted_data = encrypted_data[::-1]
with open('decoded_data.bin', 'wb') as f:
decoded_data = base64.b85decode(encrypted_data)
f.write(decoded_data)
print(f"decoded_data.bin ({len(decoded_data)})")
try:
decompressed_data = zlib.decompress(decoded_data)
print(f"zlib success ({len(decompressed_data)} )")
with open('decompressed_data.bin', 'wb') as f:
f.write(decompressed_data)
print("result: decompressed_data.bin")
except zlib.error as e:
print(f"zlib failed: {e}")
# print(decoded_data.hex()[:100] + '...')
得到flag
texsaw{python_4_will_never_exist_but_if_it_did_it_might_look_like_this_maybe_but_no_one_can_be_for_sure_did_yall_use_chatgpt_for_this?_let_me_know_if_so}
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 1621925986@qq.com

